

목차
1. 스케줄링(Scheduling)
1) 스케줄링 알고리즘
•
정의) CPU가 multiprogramming으로 동작할 때 여러 프로세스나 스레드가 ready 상태인 경우 실행할 프로세스를 선택하는 스케줄러(운영체제의 일부분)의 알고리즘
•
흐름
◦
과거 배치(batch) 시스템과 timesharing 시스템 시절
▪
CPU 희귀해서 현명한 스케줄링 알고리즘 개발에 많은 힘 쏟음
◦
개인용 컴퓨터(Personal Computers)의 등장
▪
하나의 활성화된 프로세스만 존재하고 CPU 빨라져 스케줄링을 심각하게 생각할 필요 없어짐
◦
고성능 workstation이나 서버 컴퓨터
▪
다수의 프로세스가 CPU 놓고 경쟁해서 스케줄링이 다시 문제가 됨.
2) Process Switching (== Context Switching)
•
정의) 실행 중인 프로세스를 바꾸는 것
◦
Running 상태의 프로세스를 끌어내리고 Ready 상태의 프로세스를 Running으로 끌어올리는 거.
•
특징) expensive함(시간 많이 걸림) → 스케줄링 잘해야함
•
과정
◦
사용자 모드에서 커널 모드로 전환
◦
프로세스 테이블에 현재 프로세스의 상태를 store함
◦
스케줄링 알고리즘 실행해 새 프로세스 선택
◦
새 프로세스의 저장 상태를 load해옴
◦
새 프로세스 수행
2. 프로세스의 행동 양태
1) 프로세스 행동
•
정의) 프로세스는 두 가지 행동을 반복함
◦
계산 행위: 프로세스가 계산 수행
I/O 행위: 프로세스가 I/O 기다림
•
버스트: 일정 시간 동안 계산이나 I/O를 수행하는 행위
◦
CPU 버스트: 계산 수행
◦
I/O 버스트: I/O 수행(CPU 사용하지 않고 I/O 요청하고 block상태로 가 기다리고 있는 것)
•
프로세스 행동(CPU 버스트 길이)에 따라 프로세스가 a, b타입으로 나뉨
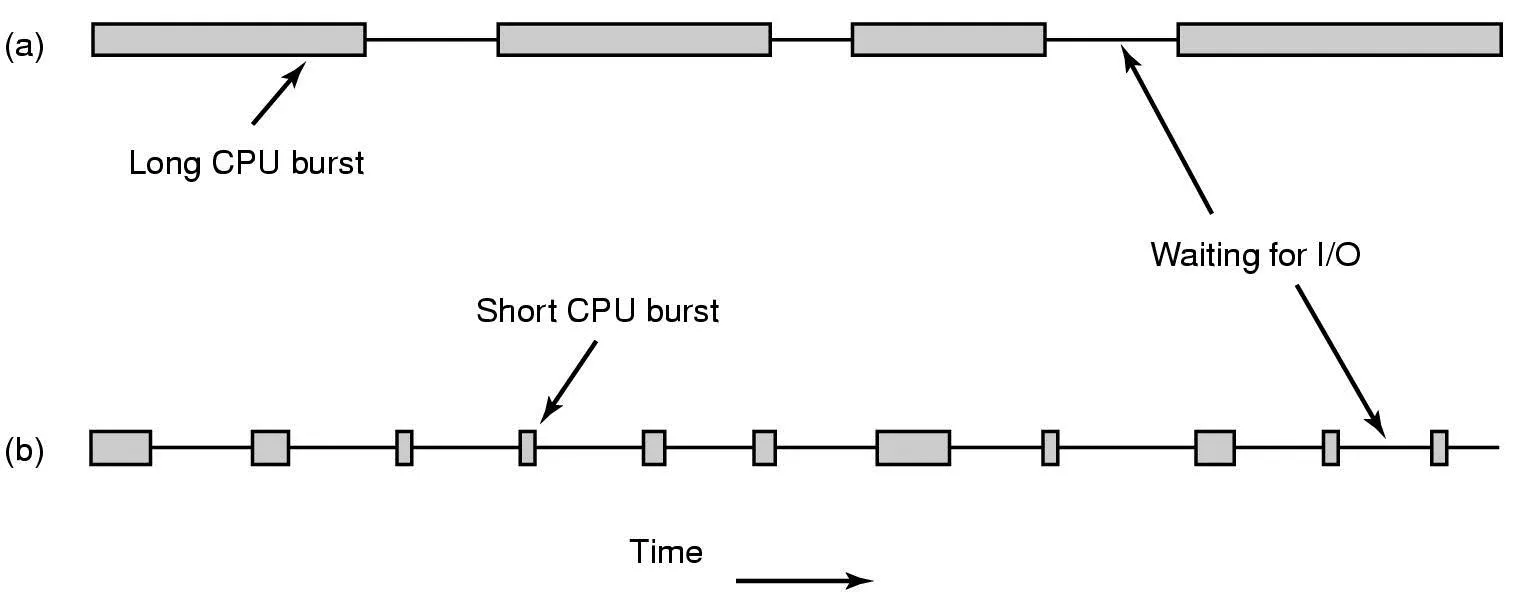
2) a타입: CPU-바운드 프로세스(Compute-bound Process)
•
정의) 긴 CPU 버스트 가져서 대부분의 시간을 계산에 소비하는 프로세스
•
특징) I/O 버스트가 드물게 나타남
3) b타입: I/O-바운드 프로세스
•
정의) 짧은 CPU 버스트 가져서 대부분의 시간을 I/O 기다리며 소비하는 프로세스
•
특징) I/O 버스트가 빈번히 나타남
◦
CPU 빨라질 수록 짧은 CPU 버스트 가지게 되어 I/O 바운드가 됨 (CPU>디스크)
◦
I/O 바운드 프로세스는 가능한 빨리 실행시켜 디스크 요청 발생시켜 디스크 바쁘게 일하게 하는게 좋음
•
주의)
◦
I/O 버스트가 길어서 I/O 바운드인게 아님 (I/O 버스트는 a, b 거의 동일함)
◦
I/O 요청 사이에 적은 계산(CPU 버스트 짧음)을 해서 I/O 바운드임
3. 스케줄링이 언제 발생하는가
•
스케줄링 결정을 내려야 하는 시점
1) 프로세스 생성할 때 → 새로운 놈(생성되어 ready로 들어옴)과 기존 놈 중 선택
•
부모 프로세스가 fork해서 자식 프로세스가 생성됨(fork 시스템콜 하면 클론 생김)
◦
스케줄링은 부모 프로세스를 계속 실행할 것인지, 자식 프로세스를 실행할 것인지 결정해야 함(둘다 Ready상태임)
2) 프로세스 종료할 때 → 대체할 놈 선택
•
프로세스가 더 이상 존재하지 않아 수행할 수 없어, Ready 상태의 다른 프로세스가 선택되어 Running 상태로 가야 함.
3) 프로세스 Block될 때 → 대체할 놈 선택
•
프로세스가 I/O, 세마포어 등과 같은 무언가 때문에 Block 상태로 가면, Ready 상태의 다른 프로세스가 선택되어 Running 상태로 가야 함.
4) I/O 인터럽트가 발생했을 때 → 새로운 놈(block에서 나와 ready로 들어옴)과 기존 놈 중 선택
•
I/O 완료되면 I/O 인터럽트가 발생함
◦
I/O 기다리며 블록되어 있던 프로세스가 이제 실행될 준비가 되어 Ready 상태로 옴
▪
새로 Ready로 온 프로세스 실행할지, 인터럽트 발생 당시 실행하던 프로세스 선택할 지 결정해야함
▪
일반적으론 인터럽트 때문에 억울하게 중지된 기존 놈 선택
4. 스케줄링 알고리즘의 카테고리
1) Clock Interrupt 처리 방법에 따라 나눈 스케줄링 알고리즘
•
Clock Interrupt
◦
하드웨어 클록이 주기적인 clock interrupt 발생시킴.
◦
매 clock interrupt 혹은 k번째 clock interrupt마다 스케줄링 결정 이루어짐.
1.
nonpreemptive(비선점) 스케줄링 알고리즘: Clock Interrupt 처리x
•
정의) 수행 프로세스는 (I/O 요청하거나 다른 프로세스 기다리기 위해) block되거나 자발적으로 CPU 내놓을 때까지 계속 수행함.
◦
수 시간동안 계속 수행해도 강제 중단 안됨
◦
Clock interrupt 발생하지 않아도 문제 없음.
2.
preemptive(선점형) 스케줄링 알고리즘: Clock Interrupt 처리o
•
정의) 수행 프로세스는 할당된 시간을 넘지 않는 범위에서 수행함.
◦
할당된 시간 다 되면 중단됨(Ready로 끌어내려짐). 스케줄러가 다른 프로세스를 Running으로 올림.
◦
할당된 시간 다 됐을 때 스케줄러가 CPU 제어 회복해서 위의 동작 하려면 Clock interrupt가 꼭 발생해야 함.
2) 스케줄링 알고리즘을 필요로 하는 환경
1.
배치(Batch) 시스템
•
정의) nonpreemptive나 긴 시간 주기의 preemptive 알고리즘 사용해 각 프로세스가 오랫동안 CPU 사용할 수 있게 해줌.
•
특징)
◦
process switch 줄여서 성능 향상 (CPU가 대부분 시간을 프로세스 수행하는 데 사용해서)
◦
공평함
◦
은행, 보험회사 등 정기적인 작업 수행 (빠른 응답 필요 x)
2.
대화식(Interactive) 시스템
•
정의) preemptive 알고리즘 필수로 사용해 한 프로세스가 CPU 독점하는 것 방지함.
•
특징)
◦
프로그램 버그로 다른 프로세스가 영원히 수행 불가능하게 되는 상황 막음
◦
다수 사용자와 interaction할 때 각 사용자의 프로세스를 빠르게 switching해줘야 사용자 입장에서 차례가 빨리빨리 와서 interaction 잘된다고 느낌
◦
서버 (다수 사용자가 빠른 응답 원함)
3.
실시간(Real time) 시스템 [참고]
•
정의) 프로세스는 자기가 오래 수행되지 않을 거란걸 알고서 보통 알아서 일 끝나면 블락함. preemptive 없어도 됨
5. 스케줄링 알고리즘의 목표
1) 모든 시스템에서 공통 목표
•
공평함
◦
각 프로세스에게 CPU를 공평하게 할당함
•
정책 집행(Policy enforcement)
◦
정책(ex. 공평함)이 잘 지켜지고 있는지 확인함
•
균형(Balance)
◦
시스템의 모든 부분이 바쁘게 유지함
2) 배치(Batch) 시스템에서 목표
•
성능(Throughput)
◦
시간 당 처리되는 job의 수를 최대화
◦
ex) 한 시간에 완료된 job의 수
•
반환시간(Turnaround time)
◦
job이 시스템에 제출된 때부터 종료까지 걸리는 시간을 최소화
•
CPU 이용률(CPU utilization) [참고]
◦
CPU가 항상 활용되도록 함
3) 대화식(Interactive) 시스템에서 목표: 사용자와 계속 interaction함
•
응답시간(Response Time)
◦
요청(Request)에 응답(Response)하는데 걸린 시간 최소화
◦
요청(Request)을 빨리하는게 중요
•
비례(Proportionality) [참고로만]
◦
사용자의 기대를 만족시킴
4) 실시간(Real time) 시스템에서 목표
•
마감시간 만족(Meeting Deadline)
◦
데드라인 만족시켜서 데이터 손실을 방지함
◦
ex) 미사일 조절에서 데드라인 놓치면 미사일이 엉뚱한데로 날아감
•
예측 가능(Predictability)
◦
멀티미디어 시스템(오디오 디코딩, 비디오 디코딩)에서 품질 저하를 방지함
◦
사용자의 품질에 대한 예측 만족시켜야 함.
6. 배치(Batch) 시스템의 스케줄링 알고리즘
•
배치 시스템과 대화식 시스템의 차이점
◦
배치: 사용자와 상호작용 x
◦
interactive: 사용자와 상호작용 o
1) 선입선출 (First-Come First-Served) → [nonpreemptive]
•
정의) (Ready큐에서) 먼저 온 프로세스가 먼저 처리(서브)함
•
특징)
◦
nonpreemptive(비선점): 한 번 수행하면 block되거나 자발적으로 내놓을 때까지 수행됨
◦
프로세스들은 요청한 순서대로 CPU 할당받음 → 공평함
◦
이를 위해서 Ready 상태의 프로세스들을 한 줄로 세워둠
▪
Ready 큐의 맨 앞에 애를 Running으로 올림
▪
새로 Ready상태가 된 애는 Ready 큐의 맨 끝에 들어감
•
장점) 이해하기 쉽고 프로그램이 쉬움
단점) [참고로만 알기]
2) 최단작업우선(Shortest Job First) → [nonpreemptive]
•
정의) (Ready큐에서) 작은 job(실행시간 짧은 job)부터 먼저 수행함
•
특징)
◦
nonpreemptive
◦
실행 시간이 미리 알려졌을 경우 적용 가능
◦
최적화(최소화)된 평균 turnaround time(반환시간) 제공함
▪
여러 job의 turnaround time(job의 제출~종료 걸리는 시간)들의 평균
▪
job의 반환시간(turnaroud time) ≠ job의 실행시간
ex) a, b, c, d 네 개의 job. 각각 실행시간은 8, 4, 4, 4분. 도착시간은 0, 0, 0, 0, 0분
◦
단, 모든 job의 도착시간이 같을 때(모든 job이 동시에 존재할 때)만 최단작업우선이 최적임
▪
그렇지 않으면 최단작업우선 써도 최소값 보장 안됨
•
ex) a, b, c, d, e 각각 실행시간은 2, 4, 1, 1, 1분. 도착시간은 0, 0, 3, 3, 3분
◦
(a) 최단작업우선 순으로 실행 (a,b,c,d,e)
과정
▪
a,b,c,d,e 반환 시간(도착~종료까지 걸린 시간)은 각각 2, 6, 4, 5, 6분
▪
평균 반환시간은 (2+6+4+5+6)/5 = 23/5 = 4.6
◦
(b) 반례 (b,c,d,e,a)
과정
▪
a,b,c,d,e 반환 시간은 각각 4, 2, 3, 4, 9분
▪
평균 반환시간은 (4+2+3+4+9)/5 = 22/5 = 4.4
3) 최단잔여시간우선(Shortest Remaining Time Next) [preemptive]
•
정의) 프로세스의 남은 실행시간이 가장 짧은 프로세스를 택함
•
특징)
◦
최단작업우선의 preemptive 버전
◦
실행시간 미리 알고 있어야함
◦
Ready큐에서 실행시간 짧은 job부터 수행함
◦
단, 중간에 새로운 job이 들어오면 새로운 job의 실행시간과 현재 Running 상태 job의 남은 실행시간을 비교함. 새로 들어온 job의 실행시간이 더 짧으면 기존 job 끌어내리고 새로운 job을 Runnign에 올림.
▪
Running 상태의 job은 항상 그 누구보다 실행시간 짧음. 누가 새로 들어와도 남은 실행시간이 걔보다 짧음.
7. 대화식(Interactive) 시스템의 스케줄링 알고리즘
1) 라운드 로빈 스케줄링(Round-Robin Scheduling)
•
정의) 각 프로세스에게 똑같은 시간할당량(Quantum) 줘서 프로세스들이 돌아가면서 수행되게 함
•
특징)
◦
preemptive
◦
process switch가 언제 일어나는가
▪
프로세스의 할당 시간이 끝나면 Ready 큐의 끝으로 보냄
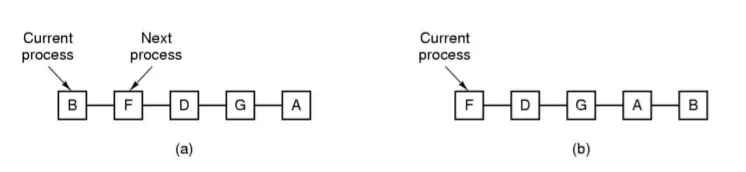
▪
할당 시간 끝나기 전에 프로세스가 block되거나 종료됨
◦
시간할당량(Quantum)의 길이에 따른 파급효과
▪
Quantum 길이 너무 짧으면
•
process switch가 빈번히 발생해 CPU 효율이 떨어짐
•
ex) 할당시간 4msec동안 작업 수행하고, process switch가 1msec 걸린다면
◦
20% CPU 시간이 관리에 소모되어 낭비됨
▪
Quantum 길이 너무 길면
•
interective request에 대해 Response time(응답 시간)이 느려짐
•
ex) 할당시간 100msec동안 작업 수행하고, process switch가 1msec 걸린다면
◦
낭비되는 시간은 1%뿐이지만
◦
50개 프로세스가 Ready 큐에 놓이고 모든 프로세스가 자신의 할당시간을 전부 수행한다면, 마지막 프로세스는 100*50msec = 5sec를 기다려야함. 응답이 너무 느림. (여러 프로세스가 빠른 응답 요구하는 서버 시스템의 경우 나쁨)
2) 우선순위 스케줄링(Priority Scheduling)
•
정의) 각 프로세스에게 우선순위를 부여해 가장 높은 우선순위 가진 프로세스부터 수행함
•
특징)
◦
preemptive (Interactive OS에서 쓰는 경우 독식 막기 위해)
높은 우선순위의 프로세스가 무한히 수행되는 것을 막는 법
◦
우선순위 부여하는 법
▪
정적: 프로세스 수행 전 사용자의 지위, 가치에 따라 우선순위 부여
•
프로세스 사용자의 위치가 무엇이느냐에 따라 우선순위 달리 줌
•
돈 많이 주는 사용자의 프로세스에게 높은 우선순위 줌
•
UNIX의 nice 커맨드 실행한 사용자의 프로세스의 우선순위 낮춤
▪
동적: 프로세스 수행 도중 I/O-bound 프로세스에게 높은 우선순위 부여
I/O-bound 프로세스는 CPU 필요로 하면 CPU 즉시 할당함 [참고로만 알기]
I/O bound 프로세스에게 좋은 서비스(높은 우선순위) 제공하는 알고리즘 [참고만 하기]
•
ex) 4개의 우선순위 클래스
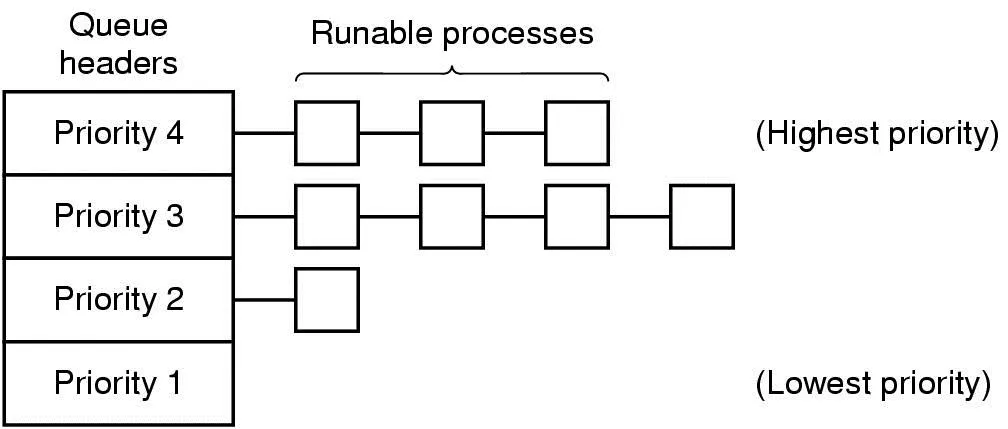
◦
우선순위 클래스: 프로세스들을 그룹으로 묶어, 그룹마다 우선순위 부여한 것 (클래스 간에 우선순위 스케줄링)
◦
각 클래스 내에선 라운드 로빈(Round-Robin) 스케줄링(Ready 상태 프로세스들을 시간 할당해서 돌아가면서 수행) 써줌
◦
우선순위 4인 클래스에 프로세스 전부 수행해 비게 되면, 우선순위 3인 클래스의 프로세스를 라운드 로빈 형태로 수행
◦
낮은 우선순위 클래스는 기아 발생해 수행 못할 수도 있음
3) 우선순위 스케줄링 사용한 시스템 예시: CTSS
•
CTSS 정의) 우선순위 클래스 쓰는 방식을 응용한 다단계 큐(Multiple Queue) 방식 사용한 시스템
•
CTSS의 문제점과 해결책
◦
문제1) process switch 매우 느림
▪
해결1) CPU-bound 프로세스에게 큰 할당시간(Quantum) 줌 → process switch 줄임
▪
But 문제2) 모든 프로세스에게 큰 할당시간 부여하면 응답 시간이 길어짐
•
해결2) 우선순위 클래스 설정
•
구체적인 해결 방법 (우선순위 클래스)
◦
가장 높은 우선순위 클래스: 1 Quantum씩 실행
◦
두 번째로 높은 우선순위 클래스: 2 Quantum씩 실행
◦
세 번째로 높은 우선순위 클래스: 4 Quantum씩 실행
◦
프로세스는 본인한테 할당된 Quantum 다 썼는데도 CPU 사용하고 있으면 클래스가 한 단계 강등됨.
•
특징)
◦
I/O 안하고 response time(응답 시간) 구애 안 받는 CPU-bound 프로세스
▪
CPU 버스트 길어서 퀀텀 다 될 때까지 계속 Running이라 점점 단계 내려감
▪
우선순위 낮은 단계로 내려감
▪
장점) 적은 switch로 큰 quantum 받음
◦
짧은 Interactive한 I/O-bound 프로세스
▪
CPU 버스트 짧아서 퀀텀 다 되기도 전에 I/O 요청해서 Block 상태로 감
▪
언젠가 I/O가 완료되어 Ready로 갈 때 강등되지 않고 원래 단계로 가서 큐 끝에 줄 섬.
▪
우선순위 높은 단계에 남아있게 됨
▪
장점) 응답시간 줄임
◦
오리지널 우선순위 클래스와 차이점
▪
우선순위 클래스: quantum 다 된 프로세스는 다시 같은 단계의 큐에 줄 섬
▪
다단계 큐: quantum 다 된 프로세스는 아래 단계의 큐에 줄 섬
•
요구하는 quantum이 짧거나 짧은 quantum만에 IO요청해서 블락된 프로세스는 계속 높은 단계에 있을 수 있음
•
요구하는 quantum이 길고 IO요청 잘 안하는 프로세스는 낮은 단계로 내려감
•
예시) 총 100 Quantum 필요로 하는 cpu-bound 프로세스
◦
100 Quantum 거의 다 혹은 다 쓸 때 동안 IO 요청 안함
◦
1 quantum 쓰고 아래 클래스로 강등되어 2 quantum 쓰고, 4 quantum 쓰고 함
◦
총 100 quantum을 써야하기에 7단계까지 내려가면 끝남
▪
1, 2, 4, 8, 16, 32, 64(의 37) → 1+2+4+8+16+32+37 = 100
▪
순수한 라운드 로빈으로 1 quantum마다 process switch했으면 100번인데, 위 방법은 process switch 7번만 하면 됨.
•
initial loading 횟수까지 포함해서 7번임!
▪
결과적으론 CPU-bound 프로세스를 높은 우선순위 클래스에 넣어주면, 적은 switch만으로 큰 quantum을 줄 수 있음 (문제 1 해결: CPU-bound에게 큰 할당 시간 줌)
◦
긴 CPU-bound 프로세스는 아래 단계로 내려가 우선순위가 낮아져 점점 덜 수행됨.
◦
짧고 interactive한 프로세스들만 높은 단계에 남아있게 되어 자주 수행됨. (문제 2 해결: 우선순위 클래스 이용해 긴 프로세스는 우선순위 낮추고, 짧은 프로세스는 우선순위 높게 유지해 응답시간 줄임)
•
예시 2) 총 100 Quantum 필요로 하는 프로세스
◦
100 quantum 쓰는 동안 10 quantum마다 io 요청함 (CPU burst: 10 quantum)
◦
1,2,3단계에서 각각 1, 2, 4 퀀텀 쓰고서, 4단계에 왔을 때 3퀀텀(총 10퀀텀 씀)만 쓰고 I/O 요청하고 Block됨
◦
4단계가 쓸 수 있는 8퀀텀을 다 안 썼기에 I/O 끝나서 Ready로 돌아올 때 4단계로 다시 돌아올 수 있음.
◦
Q) 다시 Running될 때 4단계의 8퀀텀을 사용가능한가, 아님 아까 쓰고 남은 5퀀텀만 사용가능한가??? A) 8퀀텀 사용 가능함.
•
예시 3) 총 10 퀀텀 필요로 하는 프로세스
◦
10 퀀텀 쓰는 동안 2퀀텀마다 io 요청함
◦
1단계에서 1퀀텀 쓰고, 2단계 Ready 큐로 강등됨
◦
Running될 때 2단계에서 1퀀텀만 쓰고 I/O 요청해서 Block 됨
◦
2단계가 쓸 수 잇는 2퀀텀을 다 안썼기에 I/O 끝나고 Ready로 돌아올 때 2단계 Ready 큐로 다시 돌아옴
◦
1) Running될 때 2단계에서 2퀀텀 쓰고 I/O 요청해서 Block 되면
▪
I/O 끝나고 Ready로 돌아올 때 2단계 Ready 큐로 다시 돌아옴 ?? 확실 x
◦
2) 만약 Running될 때 2단계에서 2퀀텀 쓰고 I/O 요청 안하면(퀀텀 더 쓰고 싶어하면)
▪
3단계 Ready 큐로 강등됨
4) 최단프로세스순번(Shortest Process Next)
•
정의) 과거 행동양태를 기반해 계산한, 예상 실행시간이 가장 짧은 프로세스를 먼저 실행함
•
특징)
◦
배치 시스템의 최단작업우선(Shortest Job First)의 interactive system 버전
▪
interactive 프로세스의 각 명령 실행을 하나의 Job으로 간주해 최단 작업 먼저 실행시키면 전체 응답 시간 최소화할 수 있음. 단, 실행시간을 알아야 함
•
대화식 프로세스: 명령 실행, 명령 기다림 반복
◦
평균 응답시간을 최소화함
•
실행시간 아는 법: 과거 행동을 기반으로 예상 실행 시간을 추정함. Aging 기법 사용
◦
ex) 시스템에 로그인한 터미널 여러 개 있음
▪
각 터미널에서 사용자가 command 치고 실행하고, command 치고 실행함
▪
터미널 입장에선 명령 수행이 반복적으로 일어남
▪
시스템 입장에선 여러 터미널 각각에 수행 앞두고 있는 프로세스가 있는 거임
▪
이들의 실행시간을 추정해야함. 가장 짧을 것으로 예측되는 프로세스를 수행
▪
각 터미널의 command의 실행시간을 어떻게 예측할까
•
터미널에서 전해 수행되었던 command 실행시간을 바탕으로 해서 추정함
•
Aging기법 사용
•
Aging 기법
◦
정의) 이전 예상치와 현재 측정된 값을 가중 평균해 연속적으로 다음 값을 예상하는 기법
◦
공식) a * T0 + (1 - a) * T1 → a * 추정 + (1-a) * 실제
▪
T0 : 예상했던 실행시간
•
실행할 command의 실행추정시간
▪
T1: 실제로 측정된 실행시간
•
실제로 실행해본 command의 실행시간
◦
ex) 최초 추정시간t0, 실제 실행시간 t1인 프로세스의 다음 추정 시간 구하는 법
▪
a = 1/2
•
a = 1/2 → 전 추정치와 실제 실행시간이 반반씩 영향 미침
•
a < 1/2 → 실행시간이 더 많은 영향 미침
•
a > 1/2 → 전 추정치가 더 많은 영향 미침
▪
다음 추정 시간 t0 / 2 + t1 / 2
▪
추정 시간 나열
a=1/2 | 추정시간 | 실행시간 |
t0 | t1 | |
t0/2 + t1/2 | t2 | |
t0/4 + t1/4 + t2/2 | t3 | |
t0/8 + t1/8 + t2/4 + t3/2 | t4 | |
t0/16 + t1/16 + t2/8 + t3/4 + t4/2 | t5 |
▪
실제 계산
a=1/2 | 추정시간 | 실행시간 |
20 | 30 | |
20/2 + 30/2 = 25 | 35 | |
25/2 + 35/2 = 30 | 40 | |
30/2 + 40/2 = 35 |
추정 시간, 실행 시간 더하고 2로 나눈 것과 같음
5) 보장 스케줄링(Guaranted Scheduling)
•
정의) 각 프로세스가 생성된 이후 CPU 얼마나 사용했는지 추적해 CPU 사용 가장 못한 프로세스를 꼴지 벗어날 때까지 수행함
•
특징)
◦
N개의 프로세스가 돌고 있다면 각 프로세스는 CPU의 1/N씩 공평하게 할당받도록 보장함
◦
CPU 사용량 추적하는 법
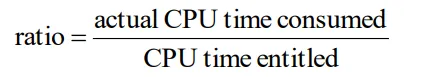
▪
actual CPU time consumed: 지금까지 CPU 쓴 시간 합한 것
▪
CPU time entitled: 한 프로세스 당 할당되는 CPU 시간 (모든 프로세스에게 동일)
▪
ratio가 0.5라면 본인에게 주어진 시간의 반만 사용한 것임
6) 복권 스케줄링(Lottery Scheduling)
•
정의) 복권 랜덤하게 발행해서 티켓 갖고 있는 프로세스 선택함
•
특징)
◦
f 비율의 티켓 가지면 f비율만큼의 자원 가짐
◦
즉각적으로 반응
◦
티켓 교환 가능
7) 공평-몫 스케줄링(Fair-Share Scheduling)
•
정의) 소유자 고려
8. 실시간(Real time) 시스템에서 스케줄링
•
정의) deadline까지 외부 이벤트에 대해 적절히 반응해야 하는 시스템
•
특징)
◦
너무 늦게 도착하는 응답은 응답 하지 않은 것과 마찬가지로 매우 나쁨
▪
ex) 음악, 비행기 자동항법, 자동화 공장의 로봇 제어, 중환자실 환자 감시
◦
프로그램을 여러 프로세스로 쪼개어 실시간 성질을 성취함
▪
프로세스들은 행동이 예측 가능하고 미리 알려져 있음
▪
프로세스들은 짧은 시간동안 활동하고 초 단위 이내에 수행 마침
•
실시간 시스템의 분류
◦
경성 실시간(Hard Real Time)
▪
데드라인 절대 놓치면 안됨
▪
비행기 자동항법, 자동화 공장의 로봇 제어
◦
연성 실시간(Soft Real Time)
▪
데드라인 놓치는거 바람직하진 않지만 허용은 됨
▪
음악
•
실시간 시스템이 응답해야 하는 이벤트
◦
주기적인 것(Periodic): 규칙적인 간격으로 발생함
◦
비주기적인 것(Aperiodic): 예측불가하게 발생함
•
스케줄가능(Schedulable)한 실시간 시스템의 기준
◦
상황: 주기적인 이벤트
▪
m개의 이벤트가 존재
▪
각 이벤트 i는 Pi의 주기마다 발생하고, 처리에 Ci초의 CPU time이 필요함
◦
주어진 상황은 아래 같을 때만 (모든 이벤트) 처리 가능함.
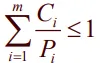
▪
각 프로세스에 의해 사용되는 cpu의 fraction의 합이 1이하일 때. 시간/주기의 합
▪
이 기준 충족하는 실시간 시스템은 Schedulable 하다고 함.
◦
ex) 주기적인 이벤트 3개
▪
m=3
▪
각 이벤트 처리에 필요한 시간 Ci : 50, 30, 100 msec
▪
각 이벤트의 주기 Pi : 100, 200, 500 msec
▪
50/100 + 30/200 + 100/500 = 0.5 + 0.15 + 0.2 = 0.85 ≤ 1 이므로 Schedulable함
▪
그림
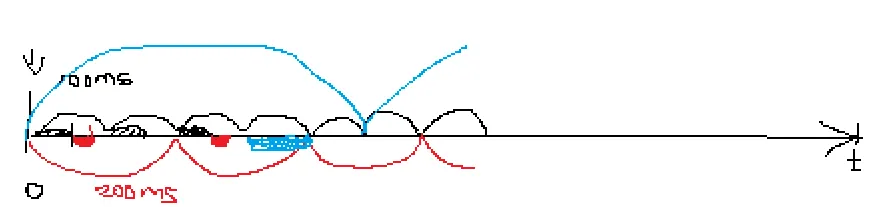
•
서연이(검정)는 100초마다 발생하는데 처리해주는데 50초씩 걸려
•
기우(빨강)는 200초마다 발생하는데 30초씩 걸려
•
채연이(파랑)는 500초마다 발생하는데 100초씩 걸려
•
채연이를 기준으로 500초 동안 서연이는 250초 썼을 거고, 기우는 75초 썼을 거야. 채연이는 100초 써서 총 425 쓰게 돼. (85%씀)
▪
문제
•
주기가 1000 msec인 네 번째 이벤트 넣고 싶음. 여전히 Schedulable하려면 어떤 조건을 만족해야하는가?
◦
0.85 + x/1000 ≤ 1
◦
x ≤ 150
◦
네 번째 이벤트가 150 msec 내에 처리 가능하면 됨
9. 정책(policy) vs 메커니즘
•
정의) 스케줄링 정책과 스케줄링 메커니즘를 분리함
•
특징)
◦
무엇이 허용되느냐와 그것이 어떻게 행해지느냐를 분리
◦
정책은 user process가, 메커니즘은 kernel이 함
▪
이전까진 kernel이 다했음
◦
스케줄링 알고리즘이 인자를 가지도록 만들어져 사용자 프로세스가 인자를 선택해 제공함
•
ex) DBMS. 자식 프로세스를 많이 만듬
◦
자식 프로세스의 중요도에 대해 부모 프로세스가 완벽히 알고 있음.
◦
이를 인자로 전달해 반영할 수 있음
▪
앞서 배운 스케줄러들은 사용자 프로세스의 입력 받아들이지 않았음
10. 스레드 스케줄링(Thread Scheduling)
1) 유저레벨 스레드 스케줄링
•
상황
◦
프로세스 A의 스레드 A1, A2, A3.
◦
각 스레드의 CPU burst가 5msec
◦
프로세스의 퀀텀은 50msec
•
유저 레벨 스레드 스케줄링
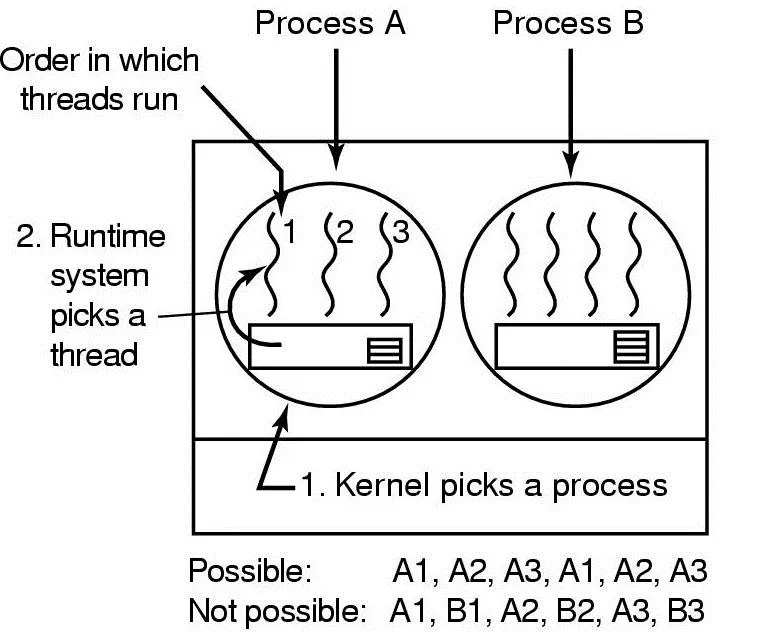
◦
스레드가 5msec씩 수행하고 CPU thread illd 콜함
◦
스레드들끼리 서로 양보하면서 수행
◦
스레드가 io 요청하면 커널은 프로세스마 봐서 프로세스 전체가 중지됨
◦
유저 레벨에서 스케줄링 일어나서 성능 좋음
2) 커널레벨 스레드 스케줄링
•
커널 레벨 스레드 스케줄링
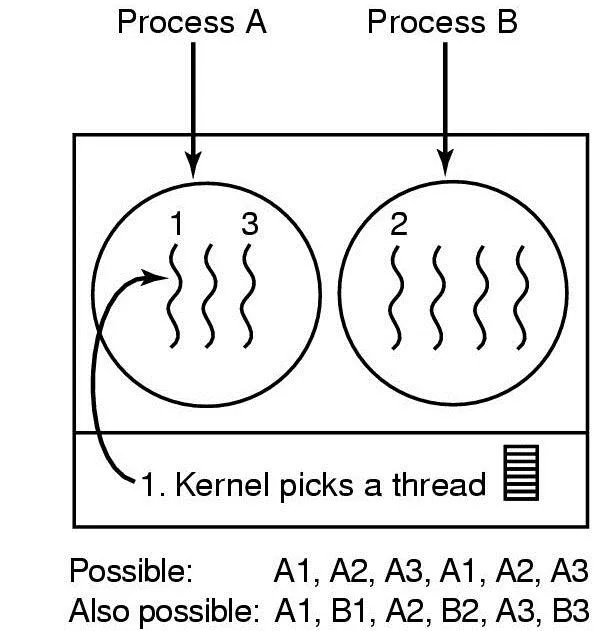
◦
커널 자체가 스레드 하나 하나의 존재를 알고 스케줄함
◦
스레드가 io 요청해도 해당 프로세스의 다른 스레드 수행 가능함
▪
커널이 스레드를 스케줄링 하는 거라 전체 프로세스를 중지시키지 않음
▪
유저 레벨과의 차이점