

Replication
•
정의) 실시간 복제본 데이터베이스 서버를 운용하는 것
◦
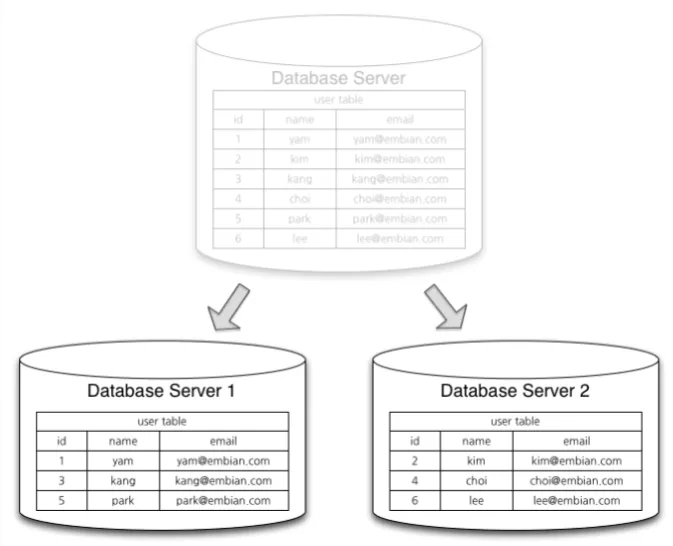
두 개 이상의 DBMS 시스템을 Master / Slave(Replica)로 나눠서 동일한 데이터를 저장함
◦
Master Node는 쓰기 작업만을 처리하고, Slave Node는 읽기 작업만을 처리함
◦
비동기 방식으로 노드들 간의 데이터를 동기화함
•
등장 배경)
◦
하나의 서버와 하나의 Database를 뒀더니 사용자가 많아졌을 때 Database가 많은 Query를 처리하기 힘든 상황이 옴.
◦
이때 Query의 대부분을 차지하는 Select를 어느 정도 해결하기 위해 등장한 방법이 Replication임
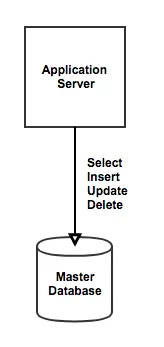
Replication 적용 전
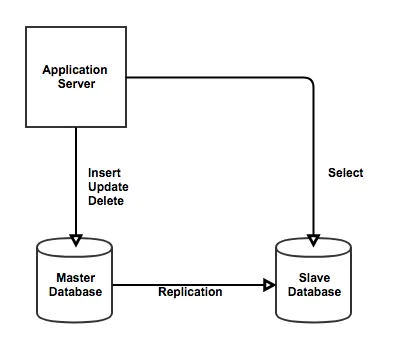
Replication 적용 후
•
방법)
1.
어플리케이션이 데이터베이스에 SQL 명령을 보내 데이터 삽입/변경/삭제 요청보냄
2.
Master가 요청 받아 binary log 생성하여 Slave 서버로 전달함
3.
Master로부터 전달받은 binary log를 데이터로 반영함
데이터 복사하는 방법 구체적으로
•
장점) 데이터 백업, DBMS 부하 분산
◦
Slave가 Master와 거의 실시간으로 동일한 데이터를 갖고 있어, 장애 복구 시 데이터 손실 최소화됨 (데이터 안정성)
▪
Slave 서버를 Master 서버로 승격시켜 기존 Master 대체하는 방식으로 복구 진행됨
◦
비동기 방식으로 운영되어 지연 시간이 거의 없다.
◦
DB 요청의 60~80% 정도가 읽기 작업이기 때문에 Replication만으로도 충분히 성능을 높일 수 있다.
•
단점)
◦
노드들 간의 데이터 동기화가 보장되지 않아 일관성있는 데이터를 얻지 못할 수 있다.
◦
Master 노드가 다운되면 복구 및 대처가 까다롭다.
Replication vs Clustering
•
Replication
◦
정의) 여러 개의 DB를 수직적(Master, Slave)인 구조로 구축하는 방식
◦
특징) 비동기 방식으로 노드들 간에 데이터 동기화
◦
장점) 비동기 방식으로 데이터가 동기화되어 지연시간이 거의 없음
◦
단점) 노드들 간의 데이터가 동기화되지 않아 일관성 있는 데이터 얻지 못할 수 있음
•
Clustering
◦
정의) 여러 개의 DB를 수평적인 구조로 구축하는 방식
◦
특징) 동기 방식으로 노드들 간에 데이터 동기화
◦
장점) 1개의 노드가 죽어도 다른 노드가 살아 있어 시스템을 장애 없이 운영할 수 있음
◦
단점) 여러 노드들 간의 데이터를 동기화하는 시간이 필요하므로 Replication에 비해 쓰기 성능이 떨어짐
AWS에서의 Database Replication
•
AWS의 RDS는 특정 데이터베이스 타입에 대해 Replication 기능을 지원함
•
복제 서버인 Replica는 읽기 전용임
•
Postgresql, Mysql, MaraiDB에 대해 지원함
Scale-out vs Scale-up
결론만 먼저 말씀드리자면, Replication은 Scale-out 기법 중 하나입니다.
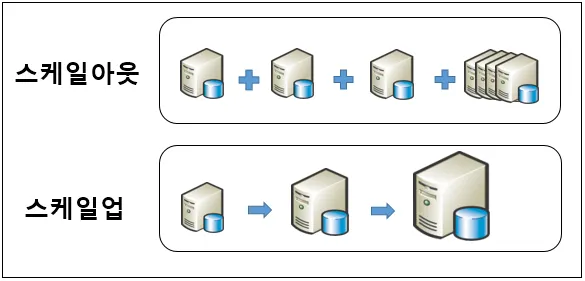
•
Scale-out
◦
정의) ‘스케일 아웃’이란 접속된 서버를 여러 대 추가하여 처리 능력을 향상하는 방법임
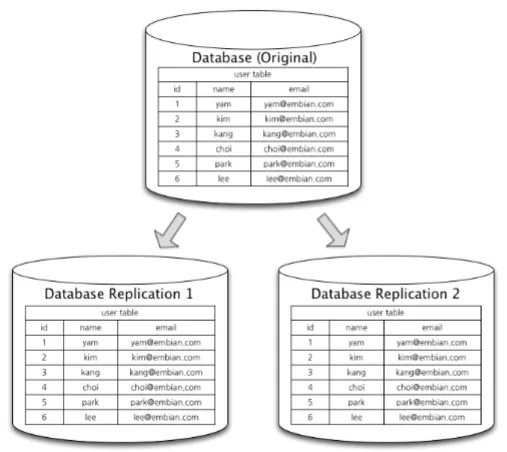
◦
특징)
▪
수평 스케일로 불리기도 함
▪
예를 들어, 하나의 처리 능력을 가진 서버에 동일한 서버 6대를 더 추가하여, 총 7의 처리 능력을 만드는 것임
◦
기법)
▪
Replication
▪
Sharding : gkskdml
•
Scale-up
◦
정의) ‘스케일 업’은 서버에 CPU나 RAM 등을 추가하거나 고성능의 부품, 서버로 교환하는 방법을 의미함
◦
특징)
▪
수직 스케일로 불리기도 함
▪
예를 들어, 하나의 처리 능력을 가진 서버 한 대를 7의 처리 능력을 가진 서버로 그 자체의 처리능력을 향상시키는 것임
•
참고)
번외) 다른 스터디원들 통해 배운 것
1. 쿠키와 세션
•
쿠키
◦
정의) 상태 정보 저장하고 유지하기 위한 기술
◦
특징) 정보를 클라이언트, 더 정확하겐 브라우저에 저장함
◦
예시) 크롬에서 로그인 했다가 edge로 들어가면 로그인 다시 해야 함
•
세션
◦
특징) 서버가 클라이언트의 상태 정보를 저장하여 클라이언트를 구분하는 기술
2. DNS
•
도메인 : 원래 지정된 인터넷 접속 주소를 www.이름.com 형태로 바꾸어 준 것
◦
www는 호스팅 주소이고, 이름.com을 도메인이라 함
•
DNS(도메인 네임 시스템)
◦
정의) 도메인 이름을 컴퓨터가 인식할 수 있는 IP 주소로 바꾸어 주는 시스템
▪
각 도메인들마다 DNS 서버(네임서버)라는 게 있음
◦
구성 요소)
1.
도메인 네임 스페이스
•
도메인 네임을 분산하여 저장하는 방식
2.
네임 서버
•
도메인 이름에 해당하는 IP 주소 찾아주는 서버
3.
리졸버 (권한 없는 DNS 서버)
•
클라이언트 요청을 네임 서버로 전달하고 네임서버에서 찾은 정보를 다시 클라이언트에게 전달하는 기능 하는 서버
◦
구조)
▪
네임 서버가 한 대만 있다면 서버 성능과 속도 측면에서 문제가 생김
▪
네임 서버를 여러 대 만든다면 도메인과 IP 주소 매핑 정보를 모든 서버에서 공유해야 함
▪
따라서 도메인을 계층적으로 구분하고 도메인과 IP주소를 분산해 저장하는 구조를 이용함
3. Optimizer
•
정의)
◦
쿼리 날릴 때 최적의 최소의 비용 소모되게 결정하는 것
◦
쿼리를 최적으로 실행하기 위해 각 테이블의 데이터가 어떤 분포로 저장되어 있는지 참조하고, 데이터를 기반으로 최적의 실행 계획을 수립해주는 것
•
과정) SQL 실행됐을 때 어떻게 컴파일러가 처리하고 최적화 어떻게 처리되는지
◦
SQL을 날리면, SQL 컴파일러에 의해 SQL이 컴파일됨
◦
SQL문이 컴파일 되면, 관계 대수가 됨. 그리고 이를 기반으로 쿼리 플랜이 생성됨
▪
질의 최적화할 때 SQL이 아니라, 관계 대수를 기반으로 한 쿼리 플랜이 고려됨
▪
쿼리 플랜
•
SQL 질의 처리할 때 관계 대수 연산자들로 이루어진 파싱 트리를 만듦
•
각각ㄱ의 관계 대수 연산자 어떻게 구현할지, 어떤 알고리즘 쓸지 결정하는 것
•
이슈)
◦
SQL 질의 처리 시 가장 중요한 것은 최적화 시키는 것
▪
해당 쿼리에서 어떤 plan들이 고려될 수 있는지
▪
각 plan들의 cost 어떻게 산정할 수 있을지
◦
이상적으론 best plan을 찾고자 하지만, 현실적으로 worst plan을 피하는 것임(NP문제)
•
쿼리 실행 절차) MySQL을 예시로 듬
◦
쿼리 실행되는 세 단계
1.
파싱 단계 : SQL을 SQL 서버가 이해할 수 있는 수준으로 잘게 쪼개서 분리(파스 트리)
•
실제로 SQL서버는 SQL문장이 아닌 SQL 파스 트리를 사용해 쿼리 실행함
2.
파스 트리 확인하면서 어떤 테이블부터 읽고 어떤 인덱스 이용할지 선택
3.
결정한 읽기 순서나 선택된 인덱스 이용해 Storage Engine을 통해 하드웨어에 있는 실제 데이터 가져옴
•
종류)
◦
규칙 기반 최적화
▪
무조건 Optimizer에 내장된 우선순위에 따라 실행 계획 수립
▪
유연하지 않아 현재는 거의 사용하지 않음
◦
비용 기반 최적화
▪
쿼리를 처리하기 위한 여러 방법 만들고 각 단위 작업의 비용 정보와 대상 테이블의 통계 정보 이용해서 각 실행 계획의 비용 산출함. 산출된 정보 이용해 가장 적은 비용 드는 실행 계획 선택해 쿼리 실행함
•
기본 데이터 처리
◦
풀 테이블 스캔
▪
풀 스캔을 하는 경우
•
테이블의 레코드 건수 너무 작아서 인덱스 통해 읽는 것보다 풀 테이블 스캔 하는 편이 더 빠른 경우
•
where절이나 on절에 인덱스 이용할만한 적절한 조건이 없는 경우
•
인덱스 레이지 스캔 할 수 있어도 조건에 일치하는 레코드가 너무 많은 경우
▪
대부분의 DBMS는 풀 테이블 스캔 실행 시 여러 개 블록이나 페이지 읽어오는 기능 내장하고 있음
◦
풀 인덱스 스캔
하루 정리
TIL 작성하기
GDSC
js 강의자료 제작
PS
Do it 1일차
솔챌 8시 회의
CS 스터디 준비(주제: Replication), 10시 스터디
•
시간 날 때 깃헙 리드미 표 안에 토글을 넣자! 배운 점에 대한 내용을 추가해주면 좋을 것 같다. 단, 줄줄 늘어놓지 말고 깔끔하게 핵심만
<details>
<summary>토글 접기/펼치기</summary>
<div markdown="1">안녕</div>
</details>
JavaScript
복사