

3월 18일, 벌써 우테코에서 한 달이 지났습니다. 한 달 간 자동차 경주 게임, 사다리 게임, 블랙잭 게임 총 세 가지 미션을 진행했습니다. 미션을 진행하며 생각한 내용들을 정리해보겠습니다.
+
4월 13일, 레벨 1의 마지막 미션인 체스 게임까지 완료한 시점에서 해당 글을 이어 작성해보겠습니다. 레벨 1 기간 동안 생긴 저의 개발 철학과 기준들을 작성하려 합니다.
1. 자동차 경주 게임
(1) SOLID 의존 관계 역전 원칙
문제가 된 코드는 아래와 같았습니다다.
// Car.java
public Car(String name, IntGenerator intGenerator) {
this.name = name;
this.intGenerator = intGenerator;
}
public static Car fromRandomGenerator(String name) {
return new Car(name, new RandomIntGenerator());
}
// Cars.java
public static Cars fromNames(List<String> names) {
List<Car> cars = names.stream()
.map(Car::fromRandomGenerator)
.toList();
return new Cars(cars);}
Java
복사
이 방식의 문제는 명확했습니다. Cars에서 Car를 생성할 때 fromRandomGenerator를 사용하고 있는 상황에선, 후에 Cars에서 Car를 생성할 때 다른 Generator도 사용하고 싶다면 (하다못해 메서드를 추가하는 식으로라도) Cars의 코드가 변경되어야 합니다. 결국 상위 모듈(사용하는 쪽)인 Cars가 하위 모듈(기능 제공하는 쪽)인 Car의 영향을 받습니다.
SOLID 원칙 중 하나인 의존관계 역전 원칙은 상위 모듈이 하위 모듈에게 의존하지 않도록 설계하라 합니다. 다시 말하자면, 상위 모듈은 하위 모듈의 구현에 의존해서는 안 됩니다. 대신 하위 모듈이 상위 모듈에서 정의한 추상 타입에 의존해야 합니다. 이를 위해선 Cars가 fromRandomGenerator, fromXXXGenerator 를 사용하는 현재 구조가 아닌, Car가 Cars에서 제공하는 Generator에 의존해야 합니다. 여기서 의존하는 건 어떻게 표현해야 할까요?
의존성 주입(DI)이라는 디자인 패턴으로 이해하면 쉽습니다.
1.
생성자 주입
2.
프로퍼티 주입
3.
메서드 주입
4.
인터페이스 주입
저는 네 번째 방식을 사용하여 아래와 같이 리팩토링해주었습니다.
// Car.java
public Car(String name, IntGenerator intGenerator) {
this.name = name;
this.intGenerator = intGenerator;
}
// Cars.java
public static Cars create(List<String> names, IntGenerator intGenerator) {
List<Car> cars = names.stream()
.map(name -> new Car(name, intGenerator))
.toList();
return new Cars(cars);
}
Java
복사
(2) 의존성 갖는 관계에서 매개변수로 객체를 넘기는 것과, 필드로 객체를 갖는 것의 차이점
1.
매개변수로 객체를 넘길 때
•
장점: 객체를 메시지처럼 주고받을 수 있음 (사용하는 측에서 단일 객체를 쓰던, 객체 리스트를 쓰던 상관 없이 사용 가능함)
◦
상관 없이 사용 가능하단 게 잘 안와닿긴 함 (ex. car를 사용하는 racing이 있다고 할 때)
◦
racing이 car를 매개변수로 받을 땐 List<Car>를 가진 누군가가 racing을 사용할 때 racing 객체를 하나만 만들고, 함수를 여러 번 호출하면 됨
◦
racing이 car를 필드로 받을 땐 List<Car>를 가진 누군가가 racing을 사용할 때 List<Racing> 처럼 객체를 여러 개 만들고, 각각의 함수를 한 번씩 호출하면 됨
•
단점: 동일한 매개변수를 메서드마다 반복해서 넣어주는 일 생기기도 함 (매개변수가 많아짐)
2.
필드로 객체를 가질 때
•
장점: 모든 메서드가 사용하는 필드의 경우, 중복 코드 줄일 수 있음
•
단점: 필드 형태가 고정되어 있어 유연하지 못함
(3) dto 재사용: 용도가 다르지만 전달할 데이터는 같은 경우, 동일한 dto를 재사용해도 되는가
1.
재사용할 때
•
장점: 코드 중복 감소
2.
재사용안하고 각각 만들어 사용할 때
•
장점: 두 기능의 스펙이 달라졌을 때 대응하기 용이함
내가 생각한 결론: 서비스 볼륨에 따라 다름
(4) 도메인과 dto 매핑하는 로직의 위치
1.
도메인에 넣을 때: dto의 필드를 도메인이 사용
•
dto의 필드가 변경되면 도메인의 코드가 바껴야 함(바람직 x)
2.
dto에 넣을 때: 도메인의 필드를 dto가 사용
•
도메인 필드가 변경되면 dto의 코드가 바껴야 함
내가 생각한 결론: 두 번째 방식이 나음
•
도메인보단 dto가 변경될 일이 더 많아서
•
dto가 많아지면 도메인이 dto를 사용하는 첫 번째 방식에선 도메인 로직이 매우 더러워져서
(5) StringBuilder의 장점
StringBuilder는 일반적으로 String보다 문자열 연결 연산 시 더 빠르단 장점이 있습니다. 각 상황에 대해 정리해보면 아래와 같습니다.
1.
루프 내에서의 문자열 연결
•
비교 : 메모리와 속도 모두 String보다 StringBuilder가 더 효율적임
•
이유
◦
String은 immutable 한 데에 반해, StringBuilder는 mutable 하다는 특징이 있음
◦
String 사용 시 루프의 각 반복마다 새로운 String 객체가 생성되어 메모리 사용량이 증가하고, 가비지 컬렉터의 부하가 커짐
◦
StringBuilder는 하나의 객체 내에서 문자열을 추가하기 때문에, 불필요한 객체 생성이 없고 메모리 사용이 최적화됨
◦
이로 인해 속도도 StringBuilder가 더 빠름
◦
좀 더 자세히 살펴보자면, String의 + 연산은 Java9부터 StringConcatFactory 에 의해 최적화 되긴 하지만 이는 단일 표현식에서만 의미가 있고, 루프에선 의미가 없음
2.
단일 표현식에서의 문자열 연결
•
비교 : 메모리 사용량과 속도 차이가 미미할 수 있으나, 일반적으로 String보다 StringBuilder가 더 효율적임
•
이유
◦
단일 표현식에서 String 연결은 컴파일러 최적화를 통해 성능이 개선될 수 있음(StringConcatFactory)
◦
그러나 복잡한 문자열 연결 또는 큰 규모의 문자열 처리에서는 StringBuilder를 사용하는 것이 메모리 할당과 가비지 컬렉션 관리 측면에서 여전히 더 우수할 수 있음
3.
예외
•
문자열 리터럴 혹은 불변 문자열 사용하여 단일 표현식에서 문자열 연결 시, String이 더 빠름
◦
컴파일 시에 문자열들 결합하여 하나의 문자의 리터럴 만듦
(6) 의미 없는 테스트
1.
테스트 코드가 테스트 코드 자신을 스스로 검증하는 느낌(바로 윗줄을 검증)이라 의미 x
Car car = new Car("pobi", intGenerator);
assertThat(car.getClass()).isEqualTo(Car.class);
Plain Text
복사
2.
이 역시 테스트 코드가 테스트 코드 자신을 스스로 검증한단 느낌을 져버리기 힘들어서 의미 x
Car car = new Car("pobi", intGenerator);
assertThat(car.getName()).isEqualTo("pobi");
Plain Text
복사
3.
어떤 값이 들어가는지 검증 필요해서 의미 o. 들어간 값이 비즈니스 로직 상 중요한 의미 가짐 (ex. 후에 count를 증가하는 로직이 존재)
Car bike = Car.createBike();
Car truck = Car.createTruck();
assertThat(bike.getTireCount()).isEqulaTo(2); // bike의 defeault name은 검증 x
assertThat(truck.getTireCount()).isEqulaTo(4);
Plain Text
복사
(7) 메서드의 일반적인 순서
메서드에도 일반적인 순서가 있습니다. 주로 아래와 같은 순서로 작성합니다.
1.
생성자
2.
정적 팩토리 메서드
3.
메서드(접근자 기준이 아닌 기능 및 역할별로 분류하여 작성)
4.
getter, setter
5.
기본 메서드(toString, equals 등)
(8) IO 작업의 동시성 이슈
System.out.println() 의 경우, PrintStream의 출력 메서드를 사용하는데,
이 메서드들은 내부적으로 동기화되어 있습니다. 따라서 애초에 동시성 이슈가 발생하지 않습니다.

scanner.nextInt() 의 경우, thread unsafe 하긴 합니다.
멀티스레드 환경에선 각 스레드에게 별도의 scanner 인스턴스를 할당해주어야 thread safe 해지죠.
다만, 싱글스레드 환경을 가정한다면 굳이 scanner의 동시성 이슈를 걱정할 이유는 없을 거 같습니다.

(9) static의 목적
메서드나 변수에 static을 붙이는 목적은
인스턴스들이 공통으로 값을 유지해야 하거나, 실행할 때 빠르게 찾아올 필요가 있어서입니다.
static 메서드는 메모리에 한 번 할당되면 프로그램이 종료될때까지 해제되지 않는다는 특징이 있기 때문입니다.
이러한 명확한 목적 없이 단순히 객체를 생성할 필요 없이 사용 가능해 보인다고 static을 남발할 시,
아래와 같은 static의 단점을 아무런 이득 없이 안고 가야 합니다.
•
static 멤버는 프로그램이 종료될 때까지 Garbage Collector로 회수되지 않기 때문에, 많은 수의 static 필드나 메서드가 존재할 경우 메모리에 영향을 미침. static 필드에 데이터가 계속해서 쌓이게 되면 OutOfMemory가 발생할 수도 있음
•
static 필드는 전역으로 관리되기 때문에 프로그램 전체에서 이 필드에 접근할 수 있고 변경할 수 있으므로 해당 필드를 추론하기 어려워 테스트하기가 까다로움
•
static 메서드는 오버라이딩이 불가함

(10) utility 사용 예
시스템 전역에 걸쳐 자주 사용되는 코드가 있다면 utility 클래스로 만들기도 합니다.
예를 들면 문자열이 null이거나 empty인지 검사하는 isEmpty,
isEmpty에 추가로 공백인지 까지 검사하는 isBlank,
컬렉션의 크기를 확인하는 size,
컬렉션의 첫 원소를 가져오는 first 등의 메서드들을 utility 클래스 내에 구현해두고 사용할 수 있습니다.
2. 사다리 게임
(1) 정적 팩토리 메서드 네이밍 컨벤션에 대한 고찰
우선 이펙티브 자바 책에서 정적 팩토리 메서드 네이밍 부분의 설명을 찾아 읽어보니 아래와 같이 나와있었습니다.
from: 매개변수를 하나 받아서 해당 타입의 인스턴스를 반환하는 형변환 메서드
•
ex. Date d = Date.from(instant);
of: 여러 매개변수를 받아 적합한 타입의 인스턴스를 반환하는 집계 메서드
•
ex. Set<Rank> faceRecards = EnumSet.of(JACK, QUEEN);
valueOf: from 과 of 의 더 자세한 버전
•
ex. BigInteger prime = BigInteger.valueOf(Integer.MAX_VALUE);
instance 혹은 getInstance: (매개변수를 받는다면) 매개변수로 명시한 인스턴스를 반환하지만, 같은 인스턴스임을 보장하지는 않는다.
•
ex. StackWalker luke = StackWalker.getInstance(options)
create 혹은 newInstance: instance 혹은 getInstance와 같지만, 매번 새로운 인스턴스를 생성해 반환함을 보장한다.
•
ex. Object newArray = Array.newInstance(classObject, arrayLen)
생각 전환 1. create의 재발견: 클래스 리터럴을 매개변수로 받음
이전엔 from/of도 인스턴스를 반환하는 거고, create도 인스턴스를 반환하는 거니 별다를게 없다 생각했습니다.
여기서 create의 설명을 다시 제대로 읽어보니 instance 혹은 getInstance와 같지만 이란 말이 있었습니다.
instance의 (매개변수를 받는다면) 매개변수로 명시한 인스턴스를 반환하지만 이란 부분이 create에도 적용된단 의미였습니다.
주어진 예시론 잘 와닿지 않아서 spring-project에 검색해보았습니다.
수많은 예시들이 나왔는데, 전부 통일되게 매개변수가 있는 경우 클래스 리터럴을 매개변수로 받는 걸 확인할 수 있었습니다.
RepositoryService service = factory.createClient(RepositoryService.class);
private static final BeanCopierKey KEY_FACTORY = (BeanCopierKey)KeyFactory.create(BeanCopierKey.class);
Plain Text
복사
따라서, create을 지금처럼 from/of와 구분없이 남발하면 안되겠단 인사이트를 얻을 수 있었습니다.
생각 전환 2. from/of의 재발견: 둘을 구분하는 의의
이전엔 from/of 사용을 통해 매개변수를 하나를 받는 것과 여러 개를 받는 것을 구분해 얻는 이득이 무엇인지 의문이었습니다. 의문을 해소하기 위해 위 설명 중 형변환 과 집계 라는 키워드에 주목해 일단 둘의 차이점을 인지했습니다.
보통 컴퓨터과학에서 집계란 여러 개의 데이터 항목을 하나의 결과로 결합하는 과정을 의미하고, 형변환은 한 개의 데이터를 다른 타입으로 변환하는 과정을 의미합니다.
여러 개를 사용할 때와 한 개를 사용할 때는 그 목적이 형변환과 집계로 다르기에 구분하는 데에 의미가 있다고 납득할 수 있었습니다.
from 과 of 라는 두 전치사가 자연어로 사용될 때도 생각해본다면,from은 주로 단일 출처를 가리킬 때 사용되고,
of는 주로 여러 조각 중 하나와 같은 복수의 구성 요소를 가리킬 때 사용됩니다.
from/of 컨벤션을 따르면 자연어처럼 읽혀 개발자가 코드를 더 직관적으로 이해하는 데에도 도움이 될 것입니다.
생각 확장. createXXX
지금과 같이 from, of, create만 단일로 사용하는 경우엔 위 컨벤션을 그대로 따르면 되겠지만, 실제로 코드를 짜다보면 아래와 같은 상황도 마주합니다.
아래 코드는 메서드 이름으로 생성하는 목적 별로 구분하고 싶고, 정적팩토리메서드가 두 개 이상이라 그 의미를 구분하고 싶을 때란 특징이 있습니다.
Lottos createSlipLottos(List<Integer> numbers) {} // 수동 로또
Lottos createQuickpickLottos(NumberGenerator numberGenerator) {} // 자동 로또
Plain Text
복사
생각 정리
제 생각엔 createSlipLottos과 createQuickpickLottos의 경우 컨벤션을 따라간다면 클래스 리터럴을 인자로 받지 않기에 fromNumbers와 fromNumberGenerator를 사용하는 게 더 타당할 수도 있습니다. 허나, 팀의 컨벤션으로 팀원들이 모두 동의했다면 createSlipLottos, createQuickpickLottos를 사용하는 것이 때론 더 가독성을 높일 수 있다 생각합니다.
(2) VO를 Record로 표현해도 될까
도메인 객체를 Record로 표현해도 되는가에 대해 리뷰어님께서 아래와 같은 의견을 내주셨다.
Record를 도메인 객체로 사용하기에는 제한 상황들이 많아서 쓰시면 안됩니다.
가장 먼저 떠오른 것은 상속을 못하기 때문에 도메인 객체로 사용하기에 제한적인 상황이 생길 수도 있단 점입니다. 클래스안에서 자동으로 만들어주는 기능들은 사용할 때는 좋지만, 정작 유지보수해야할 때는 발목을 잡는 경우가 발생합니다.
또한, openJdk 공식문서 에서 record의 목적이 불변 데이터를 전달하기 위한 캐리어임을 드러내고 있습니다. 그말은 지금 당장 사다리 미션에서 사용할 때는 특별히 제약이 없어서 사용할 수 있지만 언젠간 업데이트를 통해서 record의 본목적에 맞게 수정될 수도 있다는 말입니다. 또한 다른 개발자가 봤을 때 해당 클래스를 데이터를 전달하기 위해 만들었다고 생각했는데 안에 도메인 로직이 있다면 파악하는 비용이 발생합니다.
이러한 이유로 저는 model에 record를 사용하지 않을 것 같습니다.
리뷰어님의 말씀 중 record는 상속 기능을 제공하지 않기에 도메인 객체로 사용하기에 제한적인 상황이 생길 수 있단 의견은 자명한 사실입니다. 그렇다면 반례로써, 상속할 일이 없을 도메인 객체는 어떨까?란 궁금증이 생겼습니다.
생각 흐름 1. 모든 원시 값과 문자열을 포장한다
이번 미션의 요구사항이자 객체지향생활체조원칙 중 모든 원시 값과 문자열을 포장한다 라는 말이 있었습니다.
원시값과 문자열을 포장한 객체는 하나의 값만을 필드로 가집니다.
제 코드 상에서 원시값을 포장한 객체론 Player.java와 LadderHeight.java가 있습니다.
Player는 name(String) 이란 문자열을 포장하고 있고,
LadderHeight은 value(int) 란 원시값을 포장하고 있지요.
생각 흐름 2. 원시값을 포장한 객체를 VO로 표현 가능하다
1.
Immutable: VO는 Setter를 가지지 않고, 불변함
2.
Equality: 두 객체가 실제로 다른 객체이더라도, 논리적으로 표현하는 값이 같다면 동등성 가짐
3.
Self-Validation: 원시타입을 사용했을 때 값의 유효성을 사용하는 측에서 검사했던 것과 달리, VO는 자가 유효성 검사라는 특징 가짐
제가 원시타입을 포장하기 위해 만든 Player와 LadderHeight은 위 제약사항을 만족하기에 VO 로 사용 가능합니다.
생각 흐름 3. VO를 record로 표현 가능할까? (Can I use record for value object in java?)
도메인 객체를 Entity 와 VO로 나눠 보기에 VO 역시 도메인 객체입니다. 결론적으로 도메인 객체를 VO로 표현했다면 이땐, class가 아닌 record를 사용해도 될까? 란 의문에 종착했습니다. 즉, Player와 LadderHeight이 VO라면, 지금처럼 record로 표현해도 괜찮지 않을까? 란 궁금증이었습니다.
VO의 제약사항들은 언뜻 보면 record로 표현하기 딱 좋아 보입니다. 허나, VO의 특성을 하나하나 뜯어 보면 record의 특성과 딱 맞아떨어지지 않음을 확인할 수 있습니다.
VO는 DTO와 엄연히 다른 개념이라 개념적으로 따지면 DTO처럼 데이터 전송 용도를 가진다 보기 어렵습니다. VO는 말그대로 값 자체를 표현하는 객체이기 때문입니다. 또한, VO는 DTO와 다르게 비즈니스 로직을 포함할 수 있습니다.
리뷰어님이 말씀하신 record는 데이터 전송 캐리어이기에 record로 도메인 객체를 표현 시 얻는 단점들(목적성, 통용성)이 도메인 객체의 일종인 VO에도 똑같이 적용됩니다.
생각 정리
구글에 value object를 record로 표현해도 되는가에 대해 검색해보면, 관련 레퍼런스가 꽤 뜨긴 합니다.
record 사용 시 value object에 완벽히 fit 하게 적용할 수 있다고 표현
그럼에도 저는 VO를 record로 표현할 순 있지만, record의 본질적인 목적이 VO의 목적과 다르기에
VO를 포함한 도메인 객체는 모두 record가 아닌 class로 표현해야겠단 결론에 도달했습니다.
(3) MVC패턴에서 View와 Model 레이어 간 의존
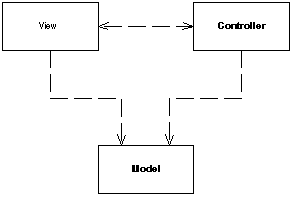

마틴 파울러가 말하는 MVC 패턴의 구조입니다(참고). MVC 패턴의 핵심 개념은 view을 model에서 분리하고, controller를 view에서 분리하는 두가지 분리입니다. 그림에서 보이는 것처럼 view에서 model을 단방향으로 의존을 하고 있긴합니다.
그럼에도 저는 각 레이어를 의식적으로 분리하려 노력합니다. 왜 각 레이어는 분리되어야 할까요? view와 model은 기본적으로 다른 관심사를 갖고 있습니다. view를 개발할 때는 UI의 메커니즘을 고려하면서 화면을 구성하는데 있죠. model은 비즈니스 정책이나 데이터베이스와 상호작용을 고려합니다. 그 사이의 간극을 메꿔주기 위해서 controller를 이용합니다. 사용자로부터 입력 받고, 모델을 조작하고, 뷰를 적절하게 업데이트 해줍니다. 그러면 Model을 통해서 가져온 정보를 가공해서 view 단에 전달해주는 책임을 가지는 곳은 view가 아니라 controller 여야할 것입니다.
view가 model을 통으로 넘겨받아서 view 단에서 객체들의 메서드를 이용해서 출력해주고 코드가 있다 해봅시다. 만약 model의 메서드에 변경이 일어나면 출력하는데 당장 변화가 생길 것입니다. 그럼 model 개발하는 사람이 view단에서도 우리 로직을 사용하고 있으니까 함부로 바꾸면 안된다는 제약사항이 생기겠죠. 점점 프로젝트의 규모가 커지면 어떻게 될까요? model의 메서드를 유지보수하는데 비용이 점점 증가하게됩니다.
서비스 볼륨에 따라서 임계점이 바뀐다고 생각합니다. 지금 당장은 와닿지 않을 규모의 프로젝트라고 생각합니다 그런데 저는 규모와 상관없이 레이어를 의식적으로 독립시키는 것이 중요하다고 생각합니다.
(4) 클래스 분리의 기준 및 시점
•
private 메서드를 테스트하고 싶을 때
-> 세부 로직이라 생각했던 부분이 핵심적인 로직인건데, 역할을 분리해줘야 할 징조일 수 있음. private 메서드가 담당하던 로직들을 새 클래스에 넣어줄지 결정하기.
•
Analyzer, Generator와 같이 -er, -or로 끝나는 객체가 꼭 필요할 때
-> 과도하거나 잘못 지고 있는 책임을 가져가서 대신 연산해줄 제3의 객체를 만들어 해결하려고 한 징조일 수 있음. 해당 역할을 맡을 더 적합한 클래스가 있는지 찾아보기.
•
한 클래스가 너무 많은 기능을 수행하고 있다고 느껴질 때
-> 클래스의 책임이 명확하지 않고, 여러 역할을 혼동해 수행하고 있단 징조일 수 있음. 책임 분리 다시 해보기.

(5) 트랜잭션 스크립트 패턴 vs 도메인 모델 패턴
•
트랜잭션 스크립트 패턴 예시
// Game.java
public GameResult play() {
int resultIndex = playLadder(index); // ... 생략
}
private int playLadder(int currentIndex) { // ... 생략
}
private int playLine(int currentIndex, Line line) { // ... 생략
}
Java
복사
•
도메인 모델 패턴 예시
// Game.java
public GameResult play() {
int resultIndex = ladder.play(index); // ... 생략
// Ladder.java
public int play(int currentPosition) {
currentPosition = line.play(currentPosition); // ... 생략
}
// Line.java
public int play(int currentPosition) { // ... 생략
}
Java
복사
객체 지향 설계를 하게 되면 도메인 모델 패턴으로 코드를 작성하게 됩니다. 상반되는 개념으로는 트랜잭션 스크립트 패턴이 있습니다. 트랜잭션 스크립트 패턴의 경우, Game.play()에 작성된 스크립트가 처음 이 로직을 파악하는 사람에게는 훨씬 가독성이 좋을 것입니다. 한 눈에 처음부터 끝까지 flow를 확인할 수 있으니까요. 그런데 만약에 play하는 로직이 조금 복잡해서 한 200줄 정도 작성해야하면 어떨까요? 작성하는 시점에서는 편할 수 있을 것 같아요 그런데 유지보수를 해야할 때 어디서부터 손을 봐야할지 파악하기가 힘들 것 같습니다. 따라서 두 가지를 병행해서 쓰는 것이 제일 가독성이 좋다고 생각합니다. 어디서는 스크립트를 관리해주고 내부에 세부 로직들은 각각의 도메인들끼리 필요한 작업을 수행하도록 말이죠.
(6) 구현체보단 인터페이스를 쓰는 게 확장에 유리해 란 명제 의심하기
기능 명세
Map에 입력한 순대로 그 순서를 보장해야 하는 기능이 있다 해봅시다.
GameResult는 사다리 실행 결과를 Player와 Prize 꼴로 저장해두고,
사용자가 결과를 보고 싶은 대상을 입력했을 때 저장해둔 값을 토대로 사다리 실행 결과를 제공하는 객체입니다.
이때, 만일 사용자가 보고 싶은 대상으로 all을 입력했다면 모든 사용자에 대한 결과 값을 제공해야 하는데,
제공하는 순서를 처음에 사용자가 입력했던 사다리 게임에 참여할 사람 순 그대로 제공하고 싶었습니다.
따라서 Player를 Key 값으로 가지는 LinkedHashMap을 사용했습니다.
구현
위 기능 명세에 맞춰 실제로 구현을 하려고 보면 두 가지 방식 중 택할 수 있습니다.
1.
GameResult가 LinkedHashMap 타입을 필드로 가지는 방식이 있고,
2.
GameResult는 Map 타입으로 필드를 가지고, 외부에서 생성자를 통해 값을 넣을 때 LinkedHashMap을 넣어주는 방식도 존재합니다.
// GameResult (2번 방식 예시)
public class GameResult {
private final Map<Player, Prize> result;
public GameResult(final Map<Player, Prize> result) {
this.result = result;
}
// Game (외부)
public GameResult play() {
LinkedHashMap<Player, Prize> result = new LinkedHashMap<>();
// 생략
return new GameResult(result);
}
Plain Text
복사
두 방식의 장단점을 간략히 적어보면 아래와 같습니다.
1.
GameResult가 Map이 아닌 LinkedHashMap 타입을 필드로 가지는 방식
•
장점) GameResult가 순서를 보장해 결과들을 제공한단 사실이 명확하게 드러남
•
단점) Map의 다른 하위 클래스는 사용 못함
1.
GameResult가 Map 타입을 필드로 가지고, 외부에서 생성자를 통해 값을 넣을 때 LikedHahsMap 넣어주는 방식
•
장점) 사용하는 측에서 GameResult 생성 시 어떤 Map을 사용할지 결정 가능해, 보다 유연하게 GameResult를 사용할 수 있음.
•
단점) 사용하는 측에서 GameResult 사용 시 어떤 Map이 사용되는지 확인하기 어려움. 예를 들면 결과들의 순서를 보장해 제공하는지, 결과들을 정렬해서 제공하는지, 바로 알아채기 어려움
제가 1번 방식을 채택한 이유는 GameResult가 결과들의 순서를 보장하는 건
변경될 일이 없을 GameResult의 정적인 특징(기능)이라 생각했기 때문입니다.
이를 GameResult를 사용하는 측보단 GameResult 내부에 명시하는 게 더 명확하다 판단했습니다.
이처럼 어떤 경우엔 구현체가 인터페이스보다 적절할 때도 있습니다. 인터페이스가 구현체보다 낫다는 전제를 언제나 규칙처럼 적용하지 맙시다.
3. 블랙잭 게임
(1) 어디까지를 view의 출력 형식(및 역할)으로 볼 것인지
도메인 이름이라면 view의 출력 형식이 아니라는 규칙을 정해볼 수 있습니다.
예를 들어, Denomination(J, K...)은 Card라는 도메인을 구성하는 요소라서 도메인 이름으로 볼 수 있고,
public class Card {
private final Suit suit;
private final Denomination denomination;
Plain Text
복사
MatchResult(WIN,LOSE...)는 사실상 model과 view 사이에 전달되는 dto 정도에만 사용되는 요소라서 도메인 이름이 아니라고 봅니다.
public record PlayerMatchResult(String name, MatchResult matchResult) {
}
Plain Text
복사
(2) Junit5 접근제한자
jUnit5 부터는 테스트 파일에 접근 제한자가 필수가 아닙니다. 실제로 공식문서를 찾아보면 아래와 같이 나와있습니다.
Class and method visibility
Test classes, test methods, and lifecycle methods are not required to be public, but they must not be private.
It is generally recommended to omit the public modifier for test classes, test methods, and lifecycle methods unless there is a technical reason for doing so – for example, when a test class is extended by a test class in another package. Another technical reason for making classes and methods public is to simplify testing on the module path when using the Java Module System.
일반적으로 테스트 클래스와 메서드에 대해 public 접근 제한자를 생략하는 게 좋다고 합니다.
즉, package private 접근 제한자를 사용하라는 것이지요.
일반적인 경우 프로덕션 코드와 테스트 코드가 같은 패키지에 있을 것이기에 가능한 이야기 같습니다.
또, pulbic 접근제한자를 표시해야 하는 상황도 언급하네요.
문서에선 테스트 클래스가 다른 패키지에 있는 테스트 클래스와 상속 관계에 있는 경우와,
자바 모듈 시스템을 사용하는 경우를 예시로 드네요.
간결성을 위해 public 생략하는 게 합리적인것 같습니다.