

시작하며
총대마켓 팀은 READ/WIRTE DB를 분리하며 Replication을 적용했다. Replication은 Amazon RDS 가 제공하는 기본 복제 기능을 사용해 구성했다. 관련한 AWS Docs 를 보면 복제 지연(Replication Lag)이 언급된다. 소스 인스턴스와 다른 AWS 리전에 읽기 전용 복제본을 생성할 때는 지연 시간이 증가할 수 있단 점을 감안해야 한다고 명시되어 있다.

총대마켓 팀은 소스 인스턴스와 다른 리전에 복제본을 생성했기에 지연 시간 증가를 분명 고려해야 한다. AWS Docs엔 지역 데이터 센터 간 네트워크 채널이 긴 경우 지연 시간이 발생한다고 나와있는데, 이 부분은 사용자인 내가 제어할 순 없기에 복제 지연을 어떻게 시뮬레이션해볼 수 있을지 고민했다. 복제 지연을 시뮬레이션 해보기 위해 MySQL에서 제공하는 복제를 직접 사용해 복제 환경을 구성하고, 의도적으로 1초의 지연 시간을 설정해보기로 했다.
Replication 이란?
Amazon RDS 읽기 전용 복제본
우선 현재 총대마켓 팀이 사용하고 있는 Amazon RDS 읽기 전용 복제본부터 알아보자. AWS Docs는 아래와 같이 설명하고 있다.
Amazon RDS 읽기 전용 복제본은 Amazon RDS 데이터베이스(DB) 인스턴스의 성능과 내구성을 높여줍니다. 읽기 전용 복제본을 사용하면 손쉽게 단일 DB 인스턴스의 용량 한도 이상으로 탄력적으로 스케일 아웃하여 읽기 중심의 데이터베이스 워크로드를 처리할 수 있습니다. 특정 소스 DB 인스턴스의 복제본을 여러 개 만들어 여러 데이터 사본이 요청하는 높은 애플리케이션 읽기 트래픽도 처리할 수 있습니다. 덕분에 전체 읽기 처리량이 향상됩니다. 필요한 경우 읽기 전용 복제본은 독립 실행형 DB 인스턴스로 승격될 수 있습니다.
MySQL, MariaDB, PostgreSQL, Oracle 및 SQL Server 데이터베이스 엔진의 경우, Amazon RDS에서 소스 DB 인스턴스의 스냅샷을 사용해 두 번째 DB 인스턴스를 생성합니다. 그런 다음 엔진의 기본 비동기식 복제 기능을 사용해 소스 DB 인스턴스가 변경될 때마다 읽기 전용 복제본을 업데이트합니다. 읽기 전용 복제본은 읽기 전용 연결만 가능한 DB 인스턴스 역할을 수행합니다. 애플리케이션을 읽기 전용 복제본에 연결하는 방법은 DB 인스턴스에 연결하는 방법과 동일합니다. Amazon RDS는 원본 DB 인스턴스의 모든 데이터베이스를 복제합니다.
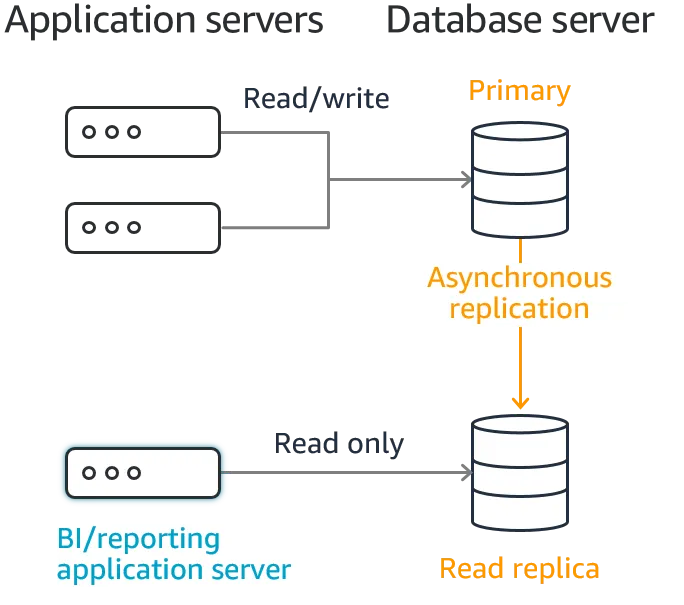
요약하자면, 읽기 전용 복제본의 장점으로 1) 탄력적 스케일 아웃 2) 높은 읽기 트래픽 처리 3) 읽기 전용 복제본의 독립 실행형 인스턴스로의 승격 을 들고 있다. 복제 방식에 대해선 1) 처음엔 스냅샷으로 인스턴스 생성 2) 이후엔 비동기 복제 기능으로 복제본 업데이트 를 들고 있다.
여기서 비동기 복제본 업데이트 부분을 더 디테일하게 알고 싶어 찾아보니, DB 엔진에 따라 복제를 다르게 구현한단 점을 알게 되었고, 총대마켓 팀이 사용 중인 MySQL에 대해선 AWS Docs에 아래와 같이 정리되어 있음을 확인했다.
•
논리적 복제를 사용함
•
바이너리 로그를 유지하며, 별도로 트랜잭션 로그를 삭제하지 않음
•
읽기 전용 복제본을 쓰기 가능하도록 활성화할 수 있음
•
병렬 복제 스레드 사용 가능함
MySQL 8.0 복제
이 뜻을 이해하는 데에 도움 받기 위해 MySQL 복제에서 사용하는 용어들 위주로 찾아보았다. 먼저 논리적 복제와 물리적 복제에 대해 알아보았다. 이를 표로 정리해보자면 아래와 같다. 요약하자면 MySQL 은 논리적 복제 방식을 택해 유연성과 확장성을 제공했다. 다만 트랜잭션을 재실행하는 논리적 특성 때문에 복제 속도가 다소 느릴 수 있다. 이를 보완하기 위해 병렬 복제와 같은 성능 최적화 기능을 활용할 수 있다. 또, MySQL은 논리적 복제이기에 읽기 전용 복제본에 대한 쓰기가 금지되지 않는다.
논리적 복제 (Logical Replication) | 물리적 복제 (Physical Replication) | |
복제 단위 | 트랜잭션, SQL 쿼리 | 데이터 파일, 디스크 블록 |
작동 방식 | 주 서버의 바이너리 로그를 읽어 복제본 서버에서 트랜잭션 실행 | 주 서버의 데이터 파일을 블록 또는 파일 단위로 복사 |
유연성 | 주 서버와 복제본의 물리적 구조가 달라도 복제 가능 | 주 서버와 복제본이 동일한 물리적 구조를 가져야 함 |
부분 복제 | 특정 테이블이나 스키마 등 부분적 복제가 가능 | 전체 데이터베이스 복제만 가능 |
복제 속도 | 트랜잭션 재실행으로 인해 느릴 수 있음 | 블록 복사 방식으로 빠른 속도 |
사용 시점 | 복잡한 복제 요구 사항이 있을 때 사용 (특정 데이터만 복제 등) | 대규모 데이터베이스의 빠른 전체 복제가 필요할 때 사용 |
데이터 무결성 | 트랜잭션 충돌 가능성이 있음 | 데이터 파일을 복사하므로 무결성 유지가 쉬움 |
성능 | 트랜잭션 재실행으로 성능이 떨어질 수 있음 | 대규모 데이터에서 더 나은 성능을 발휘함 |
다음으로 바이너리 로그와 트랜잭션 로그에 대해 알아보았다. 이를 표로 정리해보자면 아래와 같다. 바이너리 로그엔 데이터의 변경 내역뿐만 아니라 데이터베이스나 테이블의 구조 변경과 계정이나 권한의 변경 정보까지 모두 저장된다. MySQL의 복제는 바이너리 로그를 기반으로 구현됐는데, 소스 서버에서 생성된 바이너리 로그가 레플리카 서버로 전송되고 레플리카 서버에서는 해당 내용을 로컬 디스크에 저장(릴레이 로그)한 뒤 자신이 가진 데이터에 반영함으로써 소스 서버와 레플리카 서버 간에 데이터 동기화가 이뤄진다.
바이너리 로그(Binary Log) | 트랜잭션 로그(Transaction Log) | |
역할 | 외부 시스템에서 복제를 지원하고 데이터 변경 내역 기록 | 데이터베이스 내부에서 트랜잭션을 추적하고 복구에 사용 |
기록 | 커밋된 트랜잭션과 DDL,DML 변경 사항 기록 | 트랜잭션의 모든 상태(시작, 진행, 커밋, 롤백 등) 기록 |
사용 | 복제 시스템이나 외부 백업을 위해 사용 | 데이터베이스 내부 처리, 복구 및 일관성 유지 |
종류 | - | 언두 로그(Undo Log), 리두 로그(Redo Log) |
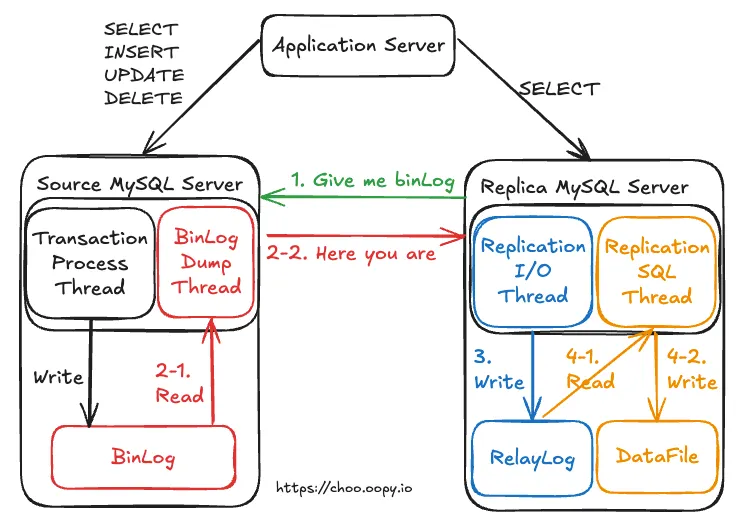
좀 더 디테일하게 동기화 과정을 알아보자면, 1) 바이너리 로그 덤프 스레드 2) 레플리케이션 I/O 스레드 3) 레플리케이션 SQL 스레드 로 총 세 스레드로 나눠 살펴볼 수 있다. 과정을 순서대로 정리해 보면 아래와 같다.
1.
레플리카 서버: 데이터 동기화를 위해 소스 서버에 접속해 바이너리 로그 정보를 요청한다.
2.
소스 서버: 레플리카 서버가 연결될 때 바이너리 로그 덤프 스레드를 생성해, 바이너리 로그 내용을 레플리카 서버로 전송한다.
3.
레플리카 서버: 레플리케이션 I/O 스레드를 생성해 소스 서버의 바이너리 로그 덤프 스레드로부터 바이너리 로그가 전달하는 이벤트를 가져와 로컬 서버의 파일(릴레이 로그)로 저장한다.
4.
레플리카 서버: 레플리케이션 SQL 스레드가 레플리케이션 I/O 스레드에 의해 작성된 릴레이 로그 파일의 이벤트들을 읽고 실행한다.
•
이벤트는 바이너리 로그에 기록된 각 변경 정보들을 뜻함
Replication Lag 이란?
AWS 지식센터에 복제 지연에 대해 검색해봤을 때 아래와 같은 AWS 측 답변을 찾아볼 수 있었다.
Amazon RDS for MySQL은 비동기 복제를 사용합니다. 즉, 복제본이 기본 DB 인스턴스를 따라잡지 못하는 경우가 있습니다. 따라서 복제 지연이 발생할 수 있습니다.
복제 지연을 모니터링하려면 바이너리 로그 파일 위치 기반 복제와 함께 Amazon RDS for MySQL 읽기 전용 복제본을 사용하세요.
Amazon CloudWatch에서 아마존 RDS의 ReplicaLag 메트릭을 확인하세요. ReplicaLag 메트릭은 SHOW SLAVE STATUS 명령의 Seconds_Behind_Master 필드 값을 보고합니다.
Seconds_Behind_Master 필드는 복제본 DB 인스턴스의 현재 타임스탬프 간의 차이를 표시합니다. 또한 복제본 DB 인스턴스의 이벤트 처리를 위해 기본 DB 인스턴스에 로깅된 원래 타임스탬프도 표시됩니다.
MySQL 복제는 Binlog Dump 스레드, IO_THREAD 및 SQL_THREAD의 세 가지 스레드에서 작동합니다. 이러한 스레드의 작동 방식에 대한 자세한 내용을 알아보려면 복제 스레드에 대한 MySQL 설명서를 참조하세요. 복제가 지연되는 경우, 복제본 IO_THREAD 또는 복제본 SQL_THREAD로 인해 지연이 발생하는지 확인하세요. 그러면 지연의 근본 원인을 확인할 수 있습니다.
복제 지연은 복제본이 기본 DB 인스턴스를 따라잡지 못하는 경우고, 이를 해결하기 위해선 앞에서 언급한 동기화 과정 속 세 스레드 중 어느 스레드가 문제인지 파악해야 한다. 어떤 복제 스레드가 지연되고 있는지 확인하기 위한 방법으로 AWS docs는 아래 방법을 알려준다.
1.
기본 DB 인스턴스에 SHOW MASTER STATUS 명령 실행해 출력 검토
•
예시
◦
File: 기본 DB 인스턴스가 바이너리 로그를 mysql-bin.066552 파일에 기록함을 알 수 있음
mysql> SHOW MASTER STATUS;
+----------------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+----------------------------+----------+--------------+------------------+-------------------+
| mysql-bin-changelog.066552| 521 | | | |
+----------------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
Plain Text
복사
2.
복제본 DB 인스턴스에 SHOW SLAVES STATUS 명령 실행해 출력 검토
•
예시 1: I/O 스레드 지연
◦
Master_Log_File:
▪
복제본 DB 인스턴스의 I/O 스레드가 바이너리 로그 파일 mysql-bin.066548에서 읽는 반면
▪
기본 DB 인스턴스는 바이너리 로그를 mysql-bin.066552 파일에 기록하므로
▪
I/O 스레드가 4개의 binLog 파일만큼 지연되고 있음을 알 수 있음
◦
Relay_Master_Log_File:
▪
복제본 DB 인스턴스의 SQL 스레드가 I/O 스레드와 같은 파일을 읽고 있으므로
▪
SQL 스레드는 정상적으로 따라가고 있음을 알 수 있음
mysql> SHOW SLAVE STATUS\G;
*************************** 1. row ***************************
Master_Log_File: mysql-bin.066548
Read_Master_Log_Pos: 10050480
Relay_Master_Log_File: mysql-bin.066548
Exec_Master_Log_Pos: 10050300
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Plain Text
복사
•
예시 2: SQL 스레드 지연
◦
Master_Log_File:
▪
복제본 DB 인스턴스의 I/O 스레드가 바이너리 로그 파일 mysql-bin.066552에서 읽고
▪
기본 DB 인스턴스도 바이너리 로그를 mysql-bin.066552 파일에 기록하므로
▪
I/O 스레드가 정상적으로 따라가고 있음을 알 수 있음
◦
Relay_Master_Log_File:
▪
복제본 DB 인스턴스의 SQL 스레드가 릴레이 로그 파일 mysql-bin.066530을 수행하는 반면
▪
I/O 스레드는 바이너리 로그 파일 mysql-bin.066552에서 읽고 있으므로
▪
SQL 스레드가 22개의 binLog 지연되고 있음을 알 수 있음
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Master_Log_File: mysql-bin.066552
Read_Master_Log_Pos: 430
Relay_Master_Log_File: mysql-bin.066530
Exec_Master_Log_Pos: 50360
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Plain Text
복사
I/O Thread 의 지연
일반적으로 I/O 스레드는 바이너리 로그 파일만 읽기 때문에 큰 복제 지연을 일으키진 않는다고 한다. 그러나 서버 간 네트워크 연결 상태나 네트워크 지연이 읽기 속도에 영향을 줄 수 있다.
SQL Thread의 지연 및 해결책
SQL 스레드가 복제 지연의 원인인 경우 아래와 같은 상황들일 확률이 높다고 한다. 각 상황 별 해결책을 매우 간략히 정리해보았다.
•
기본 DB 인스턴스의 장시간 실행되는 쿼리
◦
해결) 느린 쿼리를 더 작은 트랜잭션으로 나눠 해결
•
복제본 DB 인스턴스 클래스 크기가 충분하지 않음
◦
해결) 복제본 DB 인스턴스가 기본 DB 인스턴스와 동일하거나 더 높은 리소스 사용하도록 설정해 해결
•
기본 DB 인스턴스에서 병렬 쿼리 실행
◦
원인) 병렬 쿼리는 복제본에선 순차적으로 처리되므로 지연 발생함
◦
해결) MySQL 멀티 스레드 복제로 해결
•
복제본 DB 인스턴스의 디스크에 동기화된 바이너리 로그
◦
원인) 복제본에서 바이너리 로그를 디스크에 동기화할 때 성능 오버헤드 발생해 지연 발생함
◦
해결) sync_binlog 값 0으로 설정해 오버헤드 줄여 해결 (다만, 데이터 일관성 영향 미칠 수 있음)
•
복제본의 binlog_format이 ROW로 설정됨
◦
원인) 복제본의 binlog_format이 ROW로 설정되고 PK 없는 경우 전체 테이블 스캔해 지연 발생함
◦
해결) slave_rows_search_algorithms 파라미터를 INDEX_SCAN, HASH_SCAN으로 변경하거나, PK 추가해 해결
•
복제본 생성 지연
◦
원인) 복제본 생성할 때 복제본이 완전히 준비되기 까지 시간이 소요되어 지연 발생함
◦
해결) 수동 백업 미리 생성하고, InnoDB 캐시 워밍 기능을 활용해 지연 시간 최소화
Replication Lag 시뮬레이션 (I/O 스레드)
SQL 스레드 지연 해결책에 대해선 위에서 충분히 언급했으니, I/O 스레드 지연을 시뮬레이션해보고 이에 대한 해결책을 생각해보자. Amazon RDS MySQL 복제 기능이 기본적으로 바이너리 로그 기반 복제를 사용하기에, MySQL 복제도 바이너리 로그 방식을 사용해 구축해보자.

바이너리 로그 파일 위치 기반 복제 구축
이 방식은 MySQL에 복제 기능이 처음 도입됐을 때부터 제공된 방식으로, 레플리카 서버에서 소스 서버의 바이너리 로그 파일명과 파일 내에서의 위치로 개별 바이너리 로그 이벤트를 식별해 복제가 진행된다. 이 방식에서 주의할 점은 복제에 참여한 MySQL 서버들이 모두 고유한 server_id를 가져야 한단 점이다.
바이너리 로그에는 각 이벤트별로 해당 이벤트가 최초로 발생한 MySQL 서버를 식별하기 위한 부가정보를 함께 저장하는데, 만일 레플리카 서버의 server_id와 바이너리 로그에 쓰인 이벤트 발생지의 server_id가 같다면, 자신의 서버에서 발생한 이벤트로 간주해 적용되지 않는 문제가 발생한다.
1. 복제 설정 준비
먼저 소스 MySQL 서버의 설정 파일을 열어 아래 설정을 추가한다.
sudo vim /etc/my.cnf # 설정 파일 열기
```
# 소스 서버 설정 추가
[mysqld]
server_id = 10
log_bin = mysql-bin
default_authentication_plugin=mysql_native_password
```
sudo systemctl restart mysql # MySQL 서버 재시작해 설정 적용
Plain Text
복사
•
server_id : 고유하게 쓰기 위해 기본값 1이 아닌 다른 값을 사용하도록 설정함
•
log_bin : 바이너리 로그 파일 위치와 피일명 따로 설정함 (기본적으론 데이터 디렉터리 바로 밑에 생성됨)
다음으로 레플리카 서버도 마찬가지로 설정 파일을 열어 아래 설정을 추가한다.
sudo vim /etc/my-replica # 설정 파일 열기
```
# 레플리카 서버 설정 추가
[mysqld]
port = 3307
socket = /var/lib/mysql/mysql-replica.sock
datadir = /var/lib/mysql-replica
server_id = 11
relay_log = /var/lib/mysql-replica/mysql-relay-bin
log_slave_updates = 1
read_only = 1
default_authentication_plugin=mysql_native_password
```
sudo systemctl restart mysql # MySQL 서버 재시작해 설정 적용
Plain Text
복사
•
relay_log : 릴레이 로그 파일 위치와 파일명 따로 설정함
•
log_slave_updates : 복제에 의한 데이터 변경 사항을 자신의 바이너리 로그에 기록하도록 설정함
◦
기본적으론 복제에 의한 데이터 변경 사항은 자신의 바이너리 로그에 기록되지 않음
◦
추후 소스 서버 장애로 인해 레플리카 서버를 소스 서버로 승격할 때 고려해 설정함
•
read_only : 읽기 전용으로 사용하도록 설정함
•
relay_log_purge : 릴레이 로그 파일 자동으로 삭제하지 않고 유지하는 설정인데 적용 안함
◦
기본적으론 레플리카 서버에 적용되어 더이상 필요 없어진 릴레이 로그 파일은 삭제됨
◦
레플리카 서버 디스크 여유 공간 고려해 삭제하는 기본 설정 유지함
2. 복제 계정 준비
소스 서버에 아래 명령문을 입력해 복제용 계정을 생성한다. 레플리카 서버가 바이너리 로그 가져오려면 소스 서버에 접속해야 한다고 위에 언급했다. 복제용 계정은 이때 사용할 계정이다.
# 복제용 계정
create user 'replUser'@'%' identified by 'replPassword'
grant replication slave on *.* to 'replUser'@'%'
flush privileges
SQL
복사
3. 복제 시작 & I/O 스레드에 지연 설정
레플리카 서버에 아래 명령문을 입력해 복제 관련 정보를 등록한다. 이때, 의도적으로 I/O 스레드에서 지연이 발생하게 하기 위해 master_delay=1 설정을 추가하였다.
change master to
master_host='172.20.0.10',
master_port=3306,
master_user='replUser',
master_password='replPassword',
master_log_file='${master_log_file}',
master_log_pos=${master_log_pos},
master_delay=1; # 복제 지연 설정
SQL
복사
이 상태에서 START REPLICA 명령을 실행하면 동기화가 시작된다. 동기화가 시작된 걸 확인하고 싶다면 SHOW REPLICA STATUS 명령을 입력해 Replica_IO_Running과 Replica_SQL_Running 칼럼값이 Yes 로 되어 있는지 보면 된다.
4. 복제 지연 테스트
복제 지연으로 인해 문제가 발생하는 걸 코드로 작성해 검증해보자. 쓰기 작업 후 즉시 읽기 작업을 진행하면 소스 DB에 저장한 값이 아직 레플리카 DB에 복제되지 않아 데이터를 찾아오지 못한다.
@RequiredArgsConstructor
@Service
public class CouponService {
private final CouponRepository couponRepository;
@Transactional // 소스 DB 사용
public Long create(Coupon coupon) {
Coupon savedCoupon = couponRepository.save(coupon);
return savedCoupon.getId();
}
@Transactional(readOnly = true) // 레플리카 DB 사용
public Coupon getCoupon(Long id) {
return couponRepository.findById(id)
.orElseThrow(() -> new CouponNotFoundException(id));
}
}
@SpringBootTest
public class CouponServiceTest extends ServiceTest {
@Autowired
private CouponService couponService;
@Test
void 복제지연_발생_테스트() {
Coupon coupon = new Coupon("점심 반값 쿠폰");
couponService.create(coupon);
assertThatThrownBy(() -> couponService.getCoupon(coupon.getId())
.isInstanceOf(CouponNotFoundException.class);
}
@Test
void 복제지연_해결_테스트() {
Coupon coupon = new Coupon("점심 반값 쿠폰");
couponService.create(coupon);
Thread.sleep(2000); // 해당 라인 없어도 동작하는 게 목표
Coupon savedCoupon = couponService.getCoupon(coupon.getId());
assertThat(savedCoupon).isNotNull();
}
}
Java
복사
Replication Lag 해결책 (I/O 스레드)
Read-Your-Writes Consistency
간단하게 해결하자면 아래와 같이 해결할 수 있다. Replica DB에서 조회 시 없으면 Source DB에서 조회하는 방법인데, insert 시에만 효과가 있단 한계가 있다. update 이력은 해당 로직에서 감지할 수 없기 때문이다.
@RequiredArgsConstructor
@Service
public class CouponService {
private final CouponRepository couponRepository;
@Transactional(readOnly = true)
public Coupon getCoupon(Long id) {
return couponRepository.findById(id)
.orElseGet(() -> getCouponFromWriterDatabase(id));
}
public Coupon getCouponFromWriterDatabase(Long id) {
return transactionExecutor.executeNewTransaction(() ->
couponRepository.findById(id)
.orElseThrow(() -> new CouponNotFoundException(id))
);
}
}
@Component
public class TransactionExecutor {
@Transactional(propagation = Propagation.REQUIRES_NEW)
public <T> T executeNewTransaction(Supplier<T> supplier) {
return supplier.get();
}
}
Java
복사
Cache (vs EntityManager)
쓰기 작업과 동시에 캐시에 저장하는 방법도 있다. 이때 의문을 가져볼 수 있는 점은 캐시에서 값을 가져오는 것과 EntityManager의 1차 캐시에서 값을 가져오는 것과 무슨 차이가 있는지다. EntityManager는 하나의 세션 내에서만 유지되기에, 서로 다른 요청 간엔 캐싱이 되지 않는다는 차이가 있다.
참고
•
복제


Real MySQL 8.0, 백은빈, 이성욱

•
복제 지연 모니터링


•
복제 지연 해결


